Dans cet article nous n’allons pas traiter d’une architecture GPU spécifique, mais celle de tous en général et donc quand vous voyez le schéma que les fabricants lancent habituellement sur l’organisation de leur prochain GPU vous pouvez le comprendre sans problème. Peu importe s’il s’agit d’un GPU intégré ou dédié et de leur degré de puissance.
Organisation d’un GPU contemporain

Pour comprendre comment s’organise un GPU, il faut penser à une poupée russe ou matriochka, qui est composée de plusieurs poupées à l’intérieur. Dont on pourrait aussi parler d’un ensemble stockant une série de sous-ensembles au fur et à mesure. En d’autres termes, les GPU sont organisés de telle sorte que les différents ensembles qui les composent sont dans de nombreux cas les uns dans les autres.
Grâce à cette division, nous comprendrons beaucoup mieux quelque chose d’aussi complexe qu’un GPU, car à partir du simple, nous pouvons construire le complexe. Cela dit, commençons par le premier composant.
Ensemble A dans l’organisation GPU : unités de shader
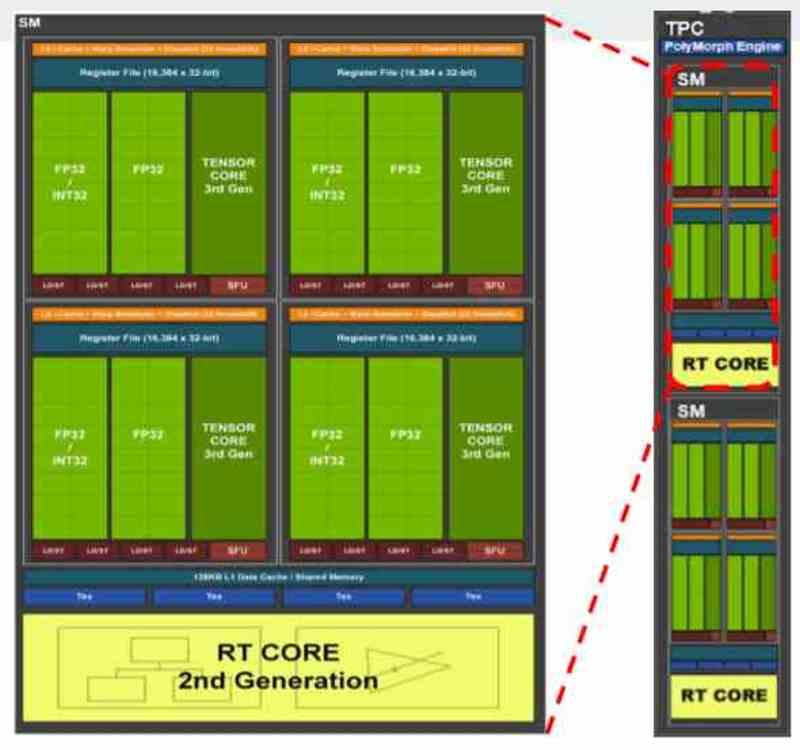
Le premier des ensembles sont les unités de shader. En eux-mêmes, ce sont des processeurs, mais contrairement aux CPU, ils ne sont pas conçus pour le parallélisme à partir d’instructions, ILP, mais à partir de threads d’exécution, TLP. Qu’il s’agisse de GPU d’AMD, de NVIDIA, d’Intel ou de toute autre marque, tous les GPU contemporains sont constitués de :
- Unités SIMD et leurs enregistrements
- Unités scalaires et leurs registres.
- Planificateur
- Mémoire locale partagée
- Unité de filtrage de texture
- Cache de données et/ou de textures de premier ordre
- Charger/stocker des lecteurs pour déplacer des données vers et depuis le cache et la mémoire partagée.
- Unité d’intersection de foudre.
- Tableaux systoliques ou unités tensorielles
- Bus d’exportation qui exporte les données de l’ensemble A vers les différents composants de l’ensemble B.
Ensemble B dans l’organisation d’un GPU: Shader Array / Shader Engine / GPC
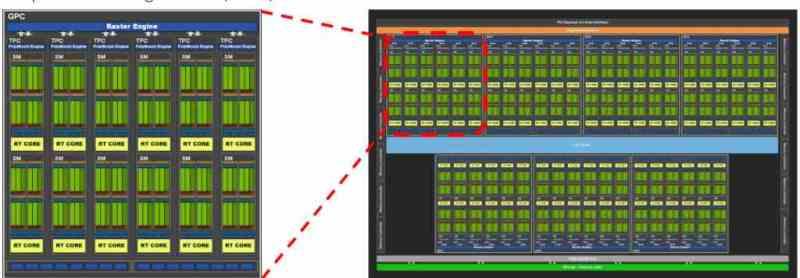
L’ensemble B inclut l’ensemble A dans son intérieur, mais ajoute initialement l’instruction et les caches constants. Dans les GPU comme dans les CPU, le cache de premier niveau est divisé en deux parties, une pour les données et l’autre pour les instructions. La différence est que dans le cas des GPU, le cache d’instructions est en dehors des unités de shader et donc ils sont dans l’ensemble B.
L’ensemble B dans une organisation GPU comprend donc une série d’unités de shader, qui communiquent entre elles via l’interface de communication commune entre elles, leur permettant de communiquer entre elles. D’un autre côté, les différentes unités de shader ne sont pas seules dans l’ensemble B, car c’est là qu’il y a plusieurs unités de fonction fixes pour le rendu des graphiques, comme maintenant.
- Unité des primitives : Celui-ci est invoqué lors du World Space Pipeline ou Geometric Pipeline, il est en charge de la tessellation de la géométrie de la scène.
- Unité de rastérisation : Il effectue la rastérisation des primitives, convertissant les triangles en fragments de pixels et son étape étant celle qui commence la soi-disant Screen Space Pipeline ou phase de rastérisation.
- ROPS : Les unités qui écrivent les tampons d’image agissent pendant deux étapes. Dans la phase raster avant la phase de texturation, ils génèrent le tampon de profondeur (Z-Buffer) tandis que dans la phase après la texturation, ils reçoivent le résultat de cette étape pour générer le tampon de couleur ou les différentes cibles de rendu (rendu différé).
Ensemble C dans l’architecture d’un GPU:
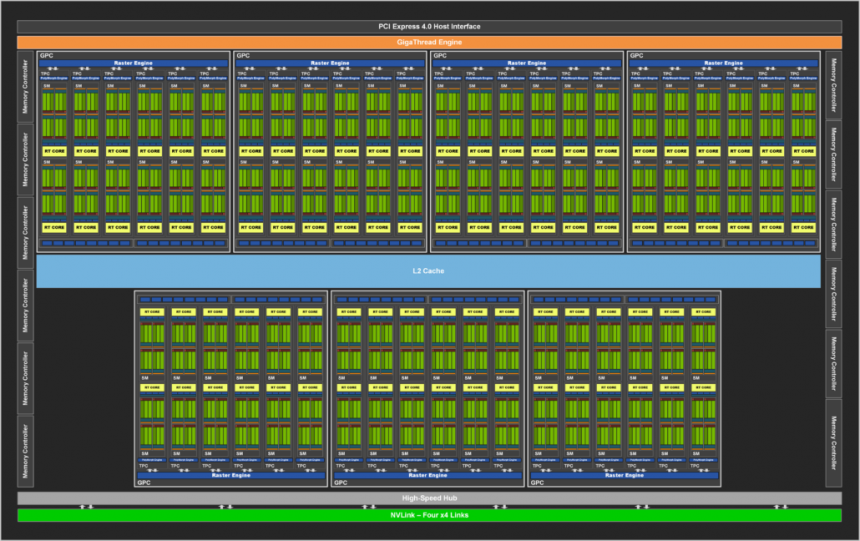
Nous avons déjà quasiment le GPU complet ou le GPU sans les accélérateurs, il se compose des composants suivants :
- Plusieurs B-Sets à l’intérieur.
- Mémoire globale partagée: Un Scratchpad et donc hors de la hiérarchie du cache pour communiquer des B Sets entre eux.
- Unité géométrique : Il a la capacité de lire des pointeurs vers la RAM qui pointent vers la géométrie de la scène, avec cela il est possible d’éliminer la géométrie non visible ou superflue afin qu’elle ne soit pas rendue inutilement dans le cadre.
- Processeurs de commandes (graphiques et informatique)
- Cache de dernier niveau : Tous les éléments du GPU sont clients de ce cache donc il doit avoir un immense anneau de communication, tous les composants du Set B ont un contact direct avec le cache L2 ainsi que tous les composants du Set C.
Le Last Level Cache (LLC) est important car c’est le cache qui nous donne la cohérence entre tous les éléments de l’Ensemble C les uns avec les autres, incluant évidemment l’Ensemble B en son sein. Non seulement cela, mais cela permet de ne pas sursaturer le contrôleur de mémoire externe car c’est la LLC elle-même, ainsi que la ou les unités MMU du GPU, qui sont responsables de la capture des instructions et des données de la RAM. Considérez le Last Level Cache comme une sorte d’entrepôt logistique dans lequel tous les éléments du Set C envoient et/ou reçoivent leurs colis et leur logistique est contrôlée par le MMU, qui est l’unité en charge de le faire.
Ensemble final, GPU complet

Avec tout cela, nous avons déjà le GPU complet, l’ensemble D comprend l’unité principale qui est le GPU en charge du rendu des graphismes de nos jeux préférés, mais ce n’est pas le plus haut niveau d’un GPU, car il nous manque une série de coprocesseurs Support. Ceux-ci n’agissent pas pour rendre les graphiques directement, mais sans eux, le GPU ne pourrait pas fonctionner. Généralement ces éléments sont :
- L’unité GFX, y compris son cache de premier niveau
- Le North Bridge ou Northbridge du GPU, s’il s’agit d’un SoC hétérogène (avec un processeur) mais avec un pool de mémoire partagée, ils utiliseront un Northbridge commun. Tous les éléments de l’ensemble D sont connectés au Northbridge
- Accélérateurs : Les encodeurs vidéo et les adaptateurs d’affichage sont connectés au Northbridge. Dans le cas du Display Adapter, c’est celui qui envoie le signal vidéo au port DisplayPort ou HDMI
- Unités DMA : S’il y a deux espaces d’adressage RAM (même avec le même puits physique), l’unité DMA permet aux données de passer d’un espace RAM à un autre. Dans le cas d’un GPU séparé, les unités DMA servent de communication avec le CPU ou d’autres GPU.
- Interface contrôleur et mémoire : Il permet de communiquer les éléments du Set D avec la RAM externe. Ils sont connectés au Northbridge et c’est le seul chemin vers la RAM externe.
Avec tout cela, vous avez déjà l’organisation complète d’un GPU, avec laquelle vous pouvez beaucoup mieux lire le schéma d’un GPU et comprendre comment il est organisé en interne.