Une façon d’identifier une carte graphique est à travers le modèle qu’elle est, avec cela nous pouvons savoir si nous sommes face à un haut de gamme au sein de sa génération ou à un autre avec des spécifications plus modestes.
DMLA
Si notre GPU provient d’AMD, nous devons rechercher ceux qui commencent par RX et éliminer les très anciens modèles portant des acronymes tels que R9, R7. Et oui, au cas où vous ne le sauriez pas, l’acronyme RX signifie R10, mais AMD a conservé le nom pour des raisons marketing. La prochaine chose que vous verrez est 3 chiffres si vous êtes entre celui qui a un GPU avec architecture GCN ou 4 chiffres s’il s’agit de RDNA, ces derniers sont meilleurs dans les spécifications et dans le cas du RX 6 × 00 vous aurez DirectX 12 Assistance ultime.
Quant au deuxième chiffre, la marque dans laquelle se trouve la carte graphique, donc un RX 6900 sera meilleur qu’un RX 6800, qui en même temps aura de meilleures caractéristiques qu’un RX 6700. Pour finir vous pouvez trouver des modèles XT , ce sont des spécifications un peu meilleures.
NVIDIA
Dans le cas où vos GPU proviennent de NVIDIA, si vous souhaitez avoir une carte graphique à jour, vous devez en rechercher une qui commence par les initiales RTX au lieu de GTX, car cela vous garantira une prise en charge complète de DirectX 12 Ultime. Quant au nombre à quatre chiffres, les deux premiers indiquent la génération et il augmente par dizaines. Ainsi un RTX 30×0 sera d’une génération plus évoluée qu’un RTX 20.
Les deux derniers chiffres indiquent la gamme à laquelle il appartient et, par conséquent, la puissance au sein d’une même architecture. Ainsi, le RTX 3090 est plus puissant que le RTX 3080. De temps en temps, NVIDIA publie des modèles Ti qui ont de meilleures spécifications que les modèles normaux et publie également des révisions après un certain temps qui portent le nom de famille SUPER.
Le GPU et ses fonctionnalités

Au centre de la carte graphique se trouve un élément matériel complexe que nous connaissons sous le nom de GPU ou Graphical Processing Unit, une unité de traitement graphique, et qui est chargé de générer les scènes qui apparaissent sur votre moniteur dans la mémoire vidéo ou VRAM qu’il entoure. La fin du processus est l’envoi de ladite image au moniteur pour que nos yeux puissent la voir et cela se fait plusieurs dizaines de fois par seconde.
Aujourd’hui, les GPU sont des morceaux de matériel qui ont un niveau de complexité dans leur architecture au niveau d’un processeur central ou CPU, cependant, il n’est pas nécessaire de connaître toutes les caractéristiques de la carte graphique pour l’achat. D’autre part, le terme est aussi souvent utilisé pour parler de l’ensemble du matériel graphique, ce qui prête à confusion malgré le fait que ce matériel ne peut pas fonctionner sans le reste des éléments qui l’entourent.
architecture GPU

Avec l’architecture, nous nous référons aux éléments environnants de celle-ci et à la manière dont ils sont distribués. L’explication est aussi simple que le fait que des architectures plus avancées permettent d’ajouter de nouvelles capacités visuelles, des performances plus élevées en mode de résolution plus élevée ou des vitesses plus élevées lors de la lecture de nos jeux préférés.
AMD, NVIDIA et Intel avec chaque nouvelle architecture améliorent les spécifications des précédentes. Dans le cas d’Intel, puisque l’ARC Alchemist est sa première carte graphique dédiée, ce n’est pas une confusion, en revanche, dans le cas de NVIDIA et AMD, plusieurs générations de cartes graphiques sont apparues ces dernières années.
De plus, le nom de l’architecture graphique n’est pas le même que le nom commercial de la carte graphique, c’est pourquoi de nombreuses fois vous trouverez certaines cartes graphiques mentionnées non pas par le nom de la box, mais par leur architecture. De la même manière, on peut aussi voir quelle est l’architecture du GPU en regardant la sérigraphie sur son encapsulation, du moins dans le cas de NVIDIA.
Taille

Parce que tout le monde n’a pas le même moniteur, ni le même budget, et pas les mêmes besoins, au sein d’une même architecture GPU, plusieurs modèles sont lancés sous forme de puces différentes. En quoi ceux-ci diffèrent-ils ? Eh bien, dans des points clés tels que :
- La interface avec mémoire vidéo et, par conséquent, la bande passante avec cela et la mémoire vidéo au total. Gardez à l’esprit que plus vous pouvez connecter de bits de bande passante, plus de puces VRAM. La quantité de mémoire autour du GPU est un bon moyen de voir si une carte graphique est inférieure à une autre.
- La quantité de unités de traitement à l’intérieur du GPUComme il est évident, moins d’espace à l’intérieur de la puce, moins d’espace peut être placé à l’intérieur et cela a pour effet d’avoir moins de puissance de calcul
Tous les GPU d’une même architecture, malgré des tailles différentes, partagent tous les éléments communs qui la définissent, mais à des niveaux de puissance différents. Le fait qu’un modèle ait une taille GPU et moins de mémoire qu’un autre se traduit également par une gamme de prix pour tous les besoins.
Unités de shader et « noyaux »
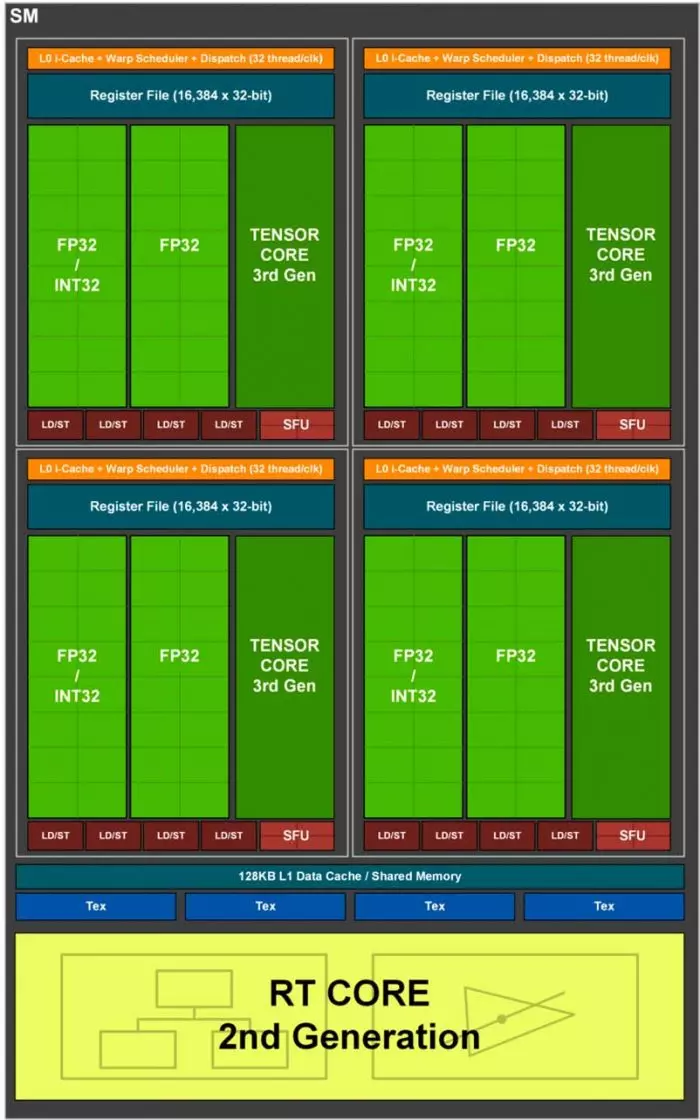
Un piège marketing que les fabricants de cartes graphiques font est d’appeler les unités de calcul à virgule flottante 32 bits comme des cœurs. De façon réaliste, un noyau est l’unité minimale qui peut exécuter une instruction complète dans un programme, donc une unité d’exécution qui n’est qu’une partie du noyau ne peut pas être considérée comme un noyau en soi.
Les unités de shader dans le cas d’AMD sont appelées unités de calcul ou processeurs de groupe de travail selon l’architecture dont nous parlons, à la place, NVIDIA utilise le terme multiprocesseurs de streaming ou SM depuis un certain temps. Cependant, lorsqu’ils parlent de cœurs dans leurs spécifications, ils font généralement référence à des unités capables de faire des calculs arithmétiques en virgule flottante 32 bits sous le nom de cœurs CUDA, NVIDIA, ou Stream Processors, AMD.
En effet, puisque ces unités de calcul sont dans ce que sont les unités de shader, le fait qu’un GPU ait plus de cœurs CUDA ou plus de Stream Processors signifie qu’il est plus puissant qu’un autre qui en a moins.
Vitesses d’horloge du GPU

Dans les caractéristiques de la carte graphique, vous allez trouver différentes vitesses d’horloge que le GPU peut atteindre à certains moments. Il faut prendre en compte que la plupart du temps le GPU restera à une vitesse d’horloge relativement faible afin de consommer le moins possible, de ne pas générer de chaleur et de ne pas allumer les ventilateurs de son système de refroidissement.
Cependant, lorsque nous démarrons une application graphiquement lourde telle que le rendu d’une scène 3D avec Blender ou lors de la lecture d’un jeu vidéo, elle démarrera à sa vitesse d’horloge de base indiquée dans ses spécifications, de sorte que le refroidissement de votre système démarrera et le GPU fonctionnera tout le temps à cette fréquence, au moins jusqu’à ce que nous en ayons besoin.
Dans certaines configurations, la carte graphique reste en veille, car le processeur comprend généralement un processeur graphique intégré à l’intérieur pour des fonctions aussi simples que le déplacement du bureau Windows.
Fréquence d’amplification

Dans certains GPU, vous verrez une vitesse d’horloge plus élevée, il s’agit de la fréquence Boost, qui fonctionne de la même manière que dans un CPU. Ainsi pendant un temps limité la vitesse d’horloge va augmenter pour accélérer le rendu de la scène ou pour faire les calculs nécessaires le plus rapidement possible. La fréquence du Boost ne peut cependant pas être atteinte longtemps, car plus la consommation est élevée plus la température dégagée est importante et cela est dangereux pour le GPU à long terme. Dans le cas des modèles AMD, il existe une fréquence Boost plus légère appelée Game Clock, qui a une durée plus longue car elle n’est pas aussi élevée que celle de Boost.
De nombreux fabricants, lorsqu’ils donnent les chiffres de leurs spécifications techniques, utilisent les taux de vitesse de la fréquence Boost comme si elle était active en permanence. S’il est vrai que de telles performances peuvent être atteintes, cela ne peut être fait que temporairement.
Unités fonctionnelles fixes
Ils sont appelés ainsi en raison du fait qu’ils remplissent toujours la même fonction, elle n’est donc pas programmable, mais est fixe à 100% du temps. La fonction de ces unités est d’effectuer une série de processus qui se répètent en continu dans chaque image lors du rendu d’une scène de manière récursive.
Taux de remplissage et texturation
Le taux de remplissage est le nombre de pixels qu’un GPU écrit sur la mémoire vidéo pour créer l’image dessus. Cela ne coïncide pas avec ceux envoyés à l’écran, car en raison de la façon dont une scène 3D est générée, un pixel en VRAM peut être écrit plusieurs fois. Pour cela, on utilise un type d’unité appelée ROPS, Raster Outputs, qui reçoit le pixel déjà traité et le copie dans la mémoire vidéo.
Le taux de texturation, d’autre part, est lié aux unités de texture et ils fonctionnent à l’envers. Pendant que le ROPS écrit dans la mémoire, l’unité de texture lit à partir des cartes de texture stockées de la VRAM pour connaître la valeur de couleur de base de ce pixel dans cet objet particulier.
Le taux de remplissage est lu en pixels par seconde, tandis que le taux de texturation est lu en texels par seconde. Accompagné d’une lettre devant le terme, où M représente des millions et G des milliards.
La puissance des fonctionnalités d’une carte graphique

La façon la plus courante de représenter la puissance de calcul d’un GPU est le nombre d’opérations à virgule flottante 32 bits qu’il peut effectuer. Eh bien, en réalité ce n’est pas comme ça, puisqu’on parle de la cadence atteinte au moment de l’exécution d’une instruction complète qui est l’addition avec multiplication ou FMA qui consiste en deux opérations par cycle d’horloge.
Alors, comment calculez-vous la puissance de …