Plus de détails : https://t.co/GIkfwrXGzV pic.twitter.com/sXGt9nbJ1S
– Underfox (@Underfox3) 3 février 2022
Comme nous le savons, jusqu’à présent, tout était AFR et SFR sur les cartes graphiques mono et multi-die, même s’il s’agissait vraiment de SLI et Crossfire déguisés. Le scénario futur sera similaire, mais il offre surtout l’avantage de puces totalement indépendantes sur un même PCB via un interposeur, tout comme AMD le fait en ce moment avec Ryzen, Threadripper et EPYC, mais en GPU.
Le nouveau brevet d’Intel montre précisément comment il va faire fonctionner ses GPU avec différents cœurs (dies), puisque les technologies de AFR et SFR Ils ne s’adaptent pas du tout comme ils le devraient malgré le fait qu’ils sont optimaux sur le papier, mais dans le monde réel, ils ont trop de problèmes. L’idée qu’Intel a eue est assez simple dans son concept, mais vraiment compliquée à mettre en œuvre dans le matériel.
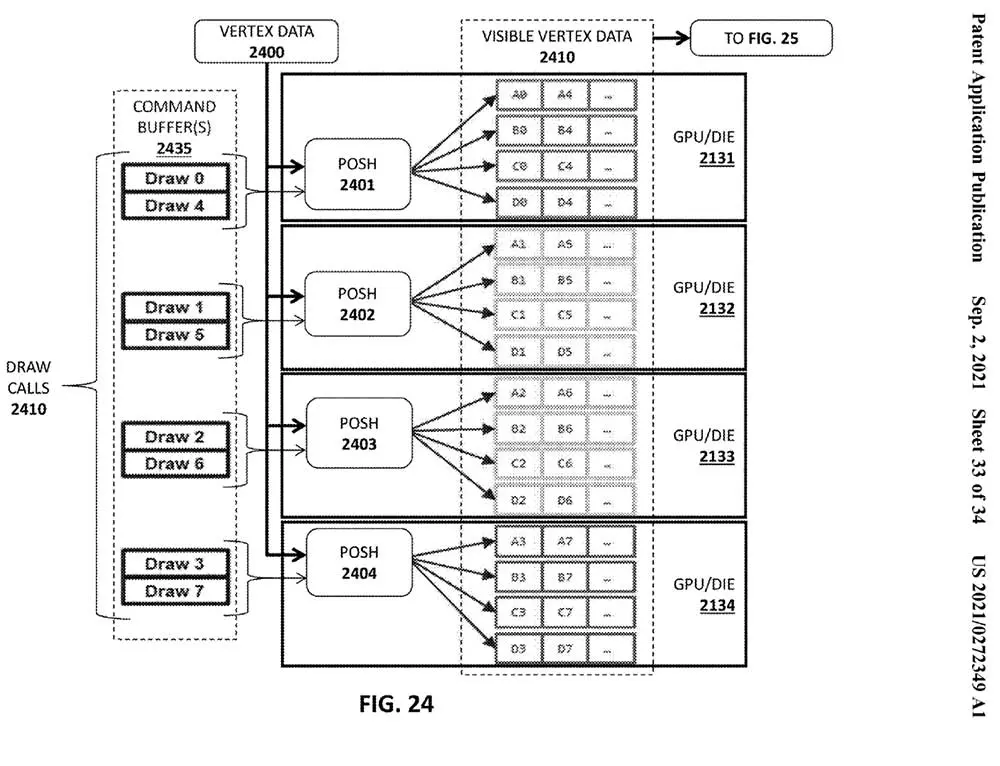
L’intention de Pat Gelsinger est d’inclure un tampon de commandes dans lequel il divise les appels de tirage et les canalise vers les matrices correspondantes via un vérificateur de rendu intégré à Tiled. Cette division semble se faire au hasard, où une fois que les matrices qui y travailleront ont été fabriquées et sélectionnées, elles seront exécutées par une nouvelle unité appelée CHIC ou Shaders de position uniquement.
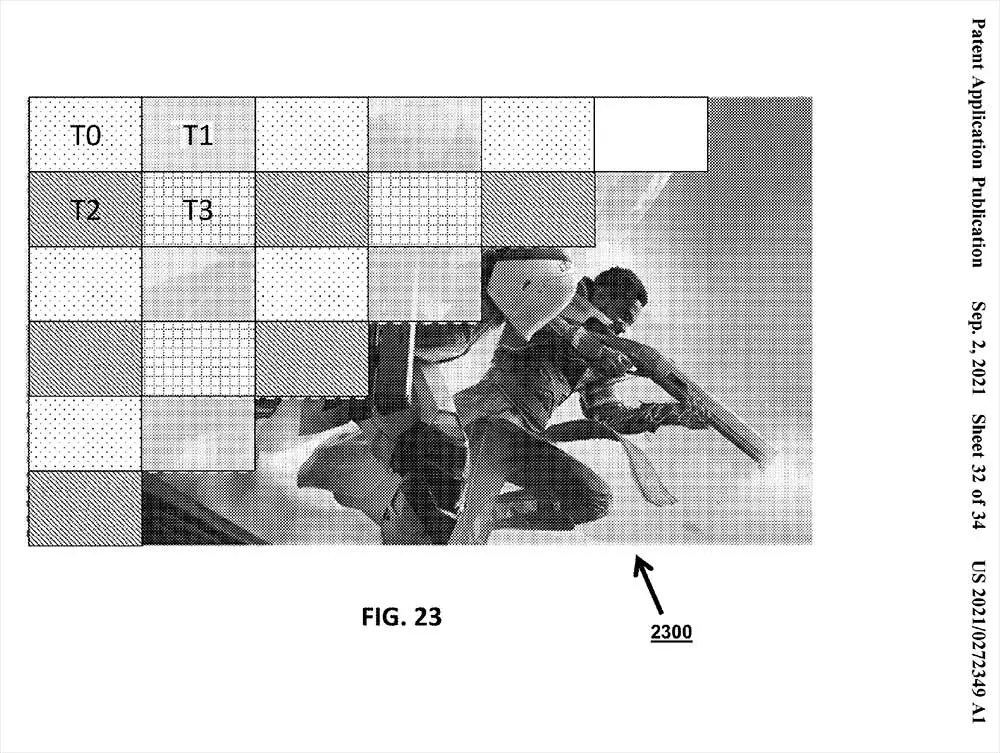
Ces unités travaillent au sein des matrices et sont chargées d’envoyer le tirage aux noyaux correspondants également de manière aléatoire. Evidemment il y a un ordre de charge de travail et surtout de représentation à l’écran, où celui-ci sera divisé en Tiled à travers le damier décrit ci-dessus ou checker. Il alloue et vérifie que chaque primitive est présente dans un espace de l’écran.
Une fois l’affectation effectuée et les données de visibilité correctes, la priorité est donnée aux primitives les plus pertinentes via le processeur de géométrie et une fois qu’il a fait son travail, les pixels sont traités de manière à ce que chaque noyau ait travaillé sur une partie du pavé en fonction de sa complexité, d’où une optimisation du temps et du calcul.
Les avantages de la mosaïque par cœur sur les GPU Intel MCM
Logiquement, le moteur de rendu et la complexité des affectations augmentent la scalabilité au fur et à mesure que des matrices sont ajoutées à l’équation, c’est-à-dire même si le système est complexe si le moteur de rendu permet une mise à l’échelle de presque 100 % plus le nombre de matrices/cœurs est élevé, plus nous ne trouverons pas de limites de performances en tant que telles.
Cela montre qu’Intel a les fondations bien établies et que l’avenir est sans aucun doute à plusieurs matrices en plus de plusieurs interposeurs, où le nombre de cœurs va progressivement évoluer et nous ne parlerons plus de Shader comme unité de mise à l’échelle en tant que telle, mais comme une unité de plus. unité de rendu où l’important sera son nombre total basé sur les cœurs dont dispose le GPU.
Bref, Intel va segmenter l’écran, l’image globale image par image en Tiled, où chacun d’eux sera travaillé par fragments qui seront plus ou moins gros selon le nombre de dies dont dispose le GPU et en même temps temps, plus les cœurs ont un dé, plus chaque Tile aura de divisions, réussissant à accomplir une tâche très coûteuse dans autant de fragments que le matériel le permetd’une complexité totale inférieure et offrant une vitesse par image plus élevée.
Un pari risqué qui franchit non pas une, mais plusieurs étapes au-delà de la technologie Tiled que NVIDIA a implémentée comme mode de rendu, le tout grâce à l’approche qu’Intel utilisera avec MCM dans ses GPU.