S’il faut parler des deux fers de lance de NVIDIA pour sa GeForce RTX il est clair qu’il s’agit du Ray Tracing et du DLSS, le premier n’est plus un avantage du fait de l’implémentation dans le RDNA 2 d’AMD, mais le second est toujours un élément différentiel. cela lui donne un grand avantage, mais tout n’est pas ce qu’il semble à première vue.
DLSS sur RTX dépend des cœurs Tensor
La première chose que nous devons prendre en compte est de savoir comment les différents algorithmes, communément appelés DLSS, tirent parti du matériel de la console et rien de mieux que de faire une analyse du fonctionnement du GPU pendant le rendu d’une trame avec le DLSS actif et sans il.
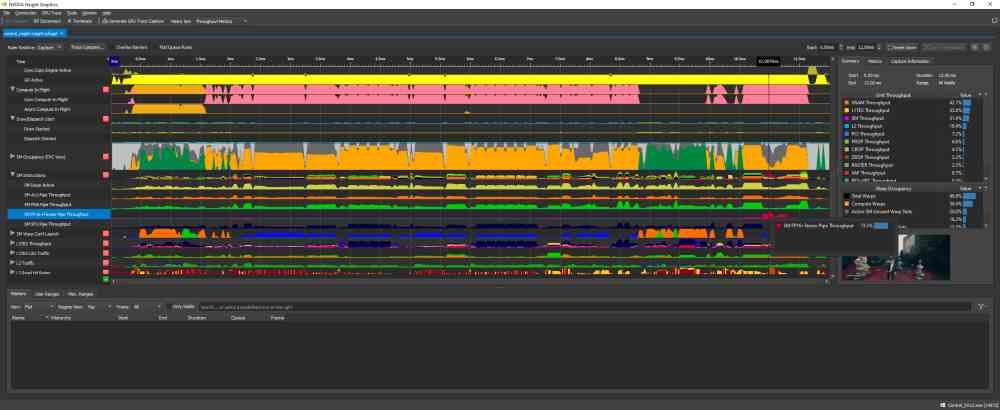
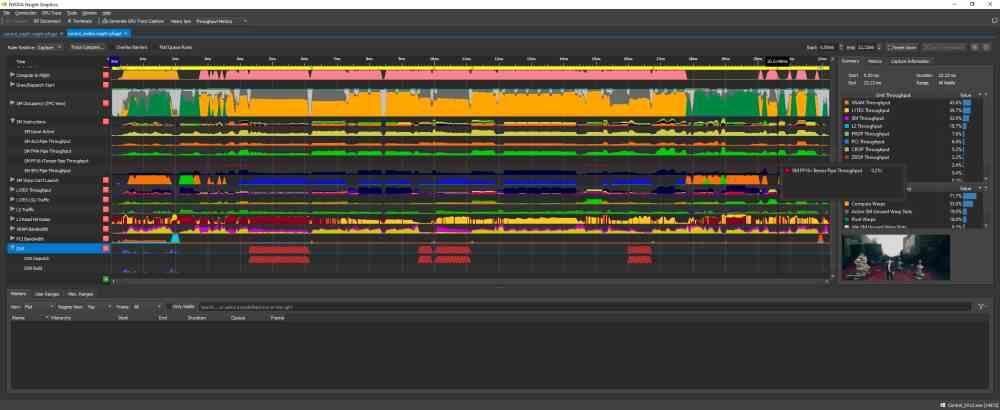
Les deux captures d’écran que vous avez au-dessus de ces images correspondent à l’utilisation de l’outil NVIDIA NSight, qui mesure l’utilisation de chacune des parties du GPU au fil du temps. Pour interpréter les graphiques, nous devons tenir compte du fait que l’axe vertical correspond au niveau d’utilisation de cette partie du GPU et l’axe horizontal le temps dans lequel l’image est rendue.
Comme vous pouvez le voir, la différence entre les deux captures d’écran du NSight est que dans l’une d’entre elles, vous pouvez voir le niveau d’utilisation de chaque partie du GPU lors de l’utilisation du DLSS et dans l’autre non. Quelle est la différence? Si on n’y regarde pas de près on verra que dans celui correspondant à l’utilisation du DLSS le graphe correspondant aux Tensor Cores est plat sauf à la fin du graphe, c’est-à-dire lorsque ces unités sont activées.
DLSS n’est rien de plus qu’un algorithme de super-résolution, qui prend une image à une résolution d’entrée donnée et produit une version de résolution plus élevée de la même image dans le processus. C’est pourquoi les cœurs Tensor, lorsqu’ils sont appliqués, sont activés en dernier, car ils nécessitent que le GPU rende l’image en premier.
Fonctionnement DLSS sur NVIDIA RTX

DLSS prend jusqu’à 3 millisecondes du temps pour rendre une image, quelle que soit la vitesse d’exécution du jeu. Si par exemple nous voulons appliquer le DLSS dans les jeux à une fréquence de 60 Hz, alors le GPU devra résoudre chaque image en:
(1000 ms / 60 Hz) -3 ms.
En d’autres termes, en 13,6 ms, en retour, nous obtiendrons une fréquence d’images plus élevée dans la résolution de sortie que celle que nous obtiendrions si nous rendions la résolution de sortie nativement au GPU.

Supposons que nous ayons une scène que nous voulons rendre à 4K. Pour cela, nous avons une GeForce RTX indéterminée qui à ladite résolution atteint 25 images par seconde, donc elle rend chacune d’entre elles à 40 ms, nous savons que le même GPU peut atteindre une fréquence d’images de 5o, 20 ms à 1080p. Notre GeForce RTX hypothétique prend environ 2,5 ms pour passer de 1080p à 4K, donc si nous activons DLSS pour obtenir une image 4K à partir d’une image à 1080p, chaque image avec DLSS prendra 22,5 ms. Avec cela, nous avons pu rendre la scène à 44 images par seconde, ce qui est supérieur aux 25 images qui seraient obtenues en résolution native.
D’un autre côté, si le GPU prend plus de 3 millisecondes pour faire sauter la résolution, alors le DLSS ne sera pas activé, car c’est le délai fixé par NVIDIA dans ses GPU RTX pour qu’ils appliquent les algorithmes DLSS. Cela rend les GPU bas de gamme limités dans la résolution à laquelle ils peuvent exécuter DLSS.
DLSS bénéficie de cœurs de mesure haute vitesse

Les Les cœurs de tension sont essentiels pour l’exécution du DLSSSans eux, cela ne pourrait pas être fait à la vitesse qui fonctionne sur le NVIDIA RTX, puisque l’algorithme utilisé pour effectuer l’augmentation de résolution est ce que nous appelons un réseau de neurones convolutif, dans la composition duquel nous n’allons pas entrer dans cet article, seulement Dire que celles-ci utilisent un grand nombre de multiplications matricielles et que les unités tensorielles sont idéales pour le calcul avec des matrices numériques, car elles sont le type d’unité qui les exécute le plus rapidement.
Dans le cas d’un film aujourd’hui, les décodeurs finissent par générer l’image initiale dans la mémoire tampon d’image plusieurs fois plus rapidement que la vitesse à laquelle elle est affichée à l’écran, donc il y a plus de temps pour mettre à l’échelle et donc cela finit par nécessiter beaucoup moins de calcul. Puissance. Dans un jeu vidéo, par contre, nous ne l’avons pas stocké sur un support comme le sera l’image suivante, mais il doit être généré par le GPU, cela réduit le temps que le scaler doit travailler.
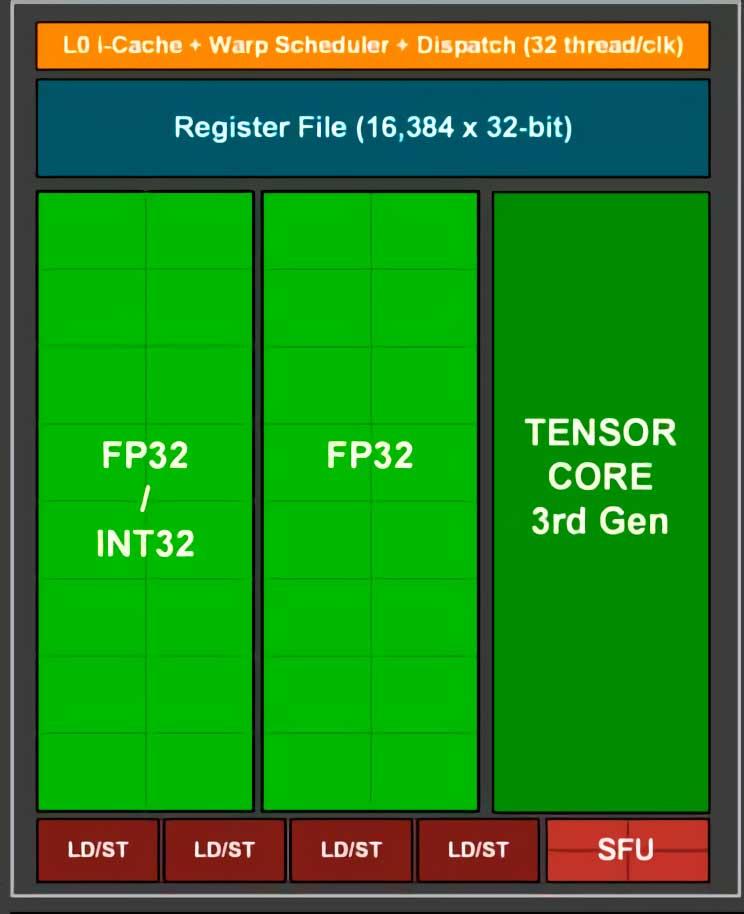
Chacun de ces Les noyaux de tension sont situés à l’intérieur de chaque unité SM et en fonction de la carte graphique que nous utilisons, sa capacité de calcul variera, en faisant varier le nombre de SM par GPU, et donc il générera l’image mise à l’échelle en moins de temps. Parce que DLSS intervient à la fin du rendu une vitesse élevée est requise pour mettre en œuvre DLSS, c’est pourquoi il est différent des autres algorithmes de super-résolution tels que ceux utilisés pour mettre à l’échelle des films et des images.
Tous les NVIDIA RTX ne fonctionnent pas de la même manière sur DLSS
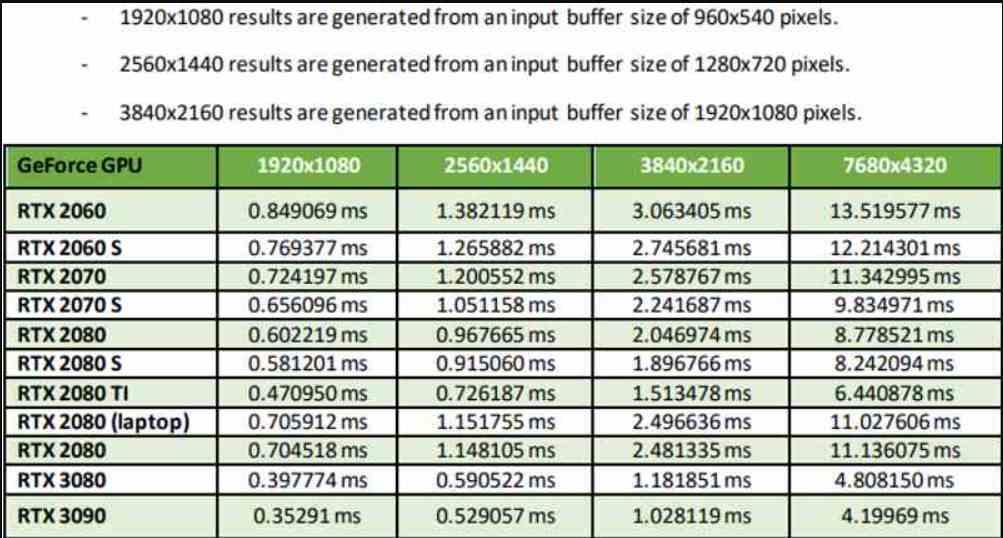
Ce tableau que vous voyez est tiré de la propre documentation de NVIDIA, où la résolution d’entrée dans tous les cas est 4 fois inférieure à la résolution de sortie, nous sommes donc en mode Performance. Hay que aclarar que existen dos modos adicionales, el Quality Mode da mejor calidad de imagen, pero requiere una resolución de entrada de la mitad de píxeles, mientras que el Ultra Performance Mode hace un escalado de 9 veces, pero tiene la peor calidad de imagen de toutes.
Comme vous pouvez le voir dans le tableau, les performances varient non seulement en fonction du GPU, mais aussi si nous prenons en compte le GPU que nous utilisons. Ce qui ne devrait pas surprendre après ce que nous avons expliqué plus tôt. Le fait qu’en mode Performance, un RTX 3090 finisse par être capable de passer de 1080p à 4K en moins de 1 ms est impressionnant pour le moins. Cela a une contrepartie qui découle d’une conclusion logique, à savoir que le DLSS sur les cartes graphiques les plus modestes fonctionnera toujours moins bien.
La cause derrière cela est claire, un GPU avec moins de puissance aura non seulement besoin de plus de temps pour rendre l’image, mais même pour appliquer le DLSS. La solution est-elle le mode Ultra Performance qui multiplie par 9 le nombre de pixels? Non, puisque DLSS exige que l’image de sortie ait une résolution d’entrée suffisante, puisque plus il y a de pixels à l’écran, il y aura plus d’informations et la mise à l’échelle sera plus précise.
Géométrie, qualité d’image et DLSS
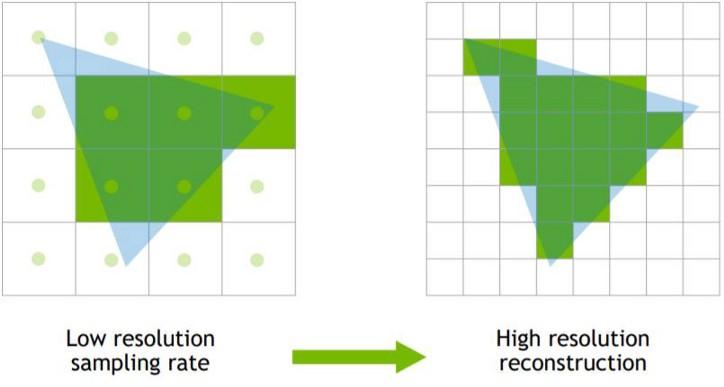
Les GPU sont conçus de telle sorte que dans l’étape Pixel / Fragment Shader, dans laquelle les pixels de chaque fragment sont colorés et les textures sont appliquées, ils le font avec des fragments de pixels 2 × 2. La plupart des GPU, lorsqu’ils ont tramé un triangle, le convertissent en un bloc de pixels qui est ensuite subdivisé en blocs de 2 × 2 pixels, où chaque bloc est envoyé à une unité de calcul.
Les conséquences sur DLSS? L’unité raster rejette généralement tous les morceaux 2 × 2 de la boîte comme étant trop petits, correspondant parfois à des détails éloignés. Cela signifie que les détails qui seraient visibles sans problème à une résolution native ne sont pas visibles dans la résolution obtenue via DLSS en raison du fait qu’ils n’étaient pas dans l’image à redimensionner.
Étant donné que DLSS nécessite une image avec autant d’informations que possible comme référence d’entrée, ce n’est pas un algorithme conçu pour générer des images à très haute résolution à partir d’images très basses, car les détails sont perdus dans le processus.
Et qu’en est-il d’AMD, peut-il émuler le DLSS?

Les rumeurs sur la super résolution du FidelityFX circulent sur le réseau depuis des mois, mais AMD ne nous a pas encore donné d’exemple réel sur le fonctionnement de son homologue du DLSS. Qu’est-ce qui rend la vie d’AMD si difficile? Eh bien, le fait que les Tensor Cores soient cruciaux pour le DLSS et dans l’AMD RX 600 il n’y a pas d’unités équivalentes, mais plutôt que SIMD over register ou SWAR est utilisé dans les ALU des unités de calcul pour obtenir des performances plus élevées dans les formats FP16 de moins de précision., mais un lecteur SIMD n’est pas un réseau systolique ou un lecteur de tension.
Dès le départ, nous parlons d’un différentiel 4 fois en faveur de NVIDIA, cela signifie que lors de la génération d’une solution similaire, il part d’un désavantage de vitesse considérable, optimisations pour le calcul des matrices à part. Nous ne discutons pas de savoir si NVIDIA est meilleur que AMD dans ce domaine, mais le fait qu’AMD lors de la conception de son RDNA 2 n’a pas donné d’importance aux unités de tenseur.
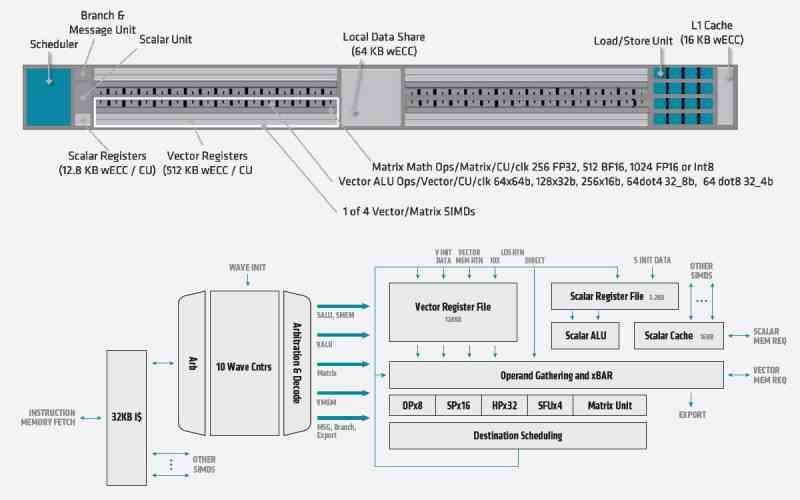
Est-ce dû à un handicap? Eh bien non, puisque paradoxalement AMD les a ajoutés à CDNA sous le nom de Matrix Core. Pour le moment, il est tôt pour parler de RDNA 3, mais espérons qu’AMD ne refera pas la même erreur en n’incluant pas l’une de ces unités. Cela n’a aucun sens de s’en passer lorsque le coût par unité de calcul ou SM n’est que de 1 mm2.
Nous espérons donc que lorsque AMD ajoutera son algorithme en raison du manque d’unités Tensor, il n’atteindra ni la précision ni la vitesse de NVIDIA, mais qu’AMD présentera une solution plus simple comme un mode Performance qui double les pixels à l’écran.