L’un des plus gros problèmes avec les systèmes CPU multicœurs que nos PC utilisent est qu’ils sont basés sur le modèle Von Neumann, c’est-à-dire qu’il n’y a qu’un seul puits de mémoire partagée. À mesure que le nombre d’unités d’exécution, de cœurs, de threads et d’autres éléments qui fonctionnent en parallèle dans un processeur augmente. De plus en plus de conflits se créent entre eux. Non seulement dans l’accès aux données, mais aussi dans les informations contenues dans les différentes adresses mémoire et donc la valeur des variables utilisées par les programmes. Il existe de nombreuses méthodes pour éviter ces conflits, l’une d’entre elles est la mémoire transactionnelle, que nous allons décrire dans cet article.
Une introduction au problème
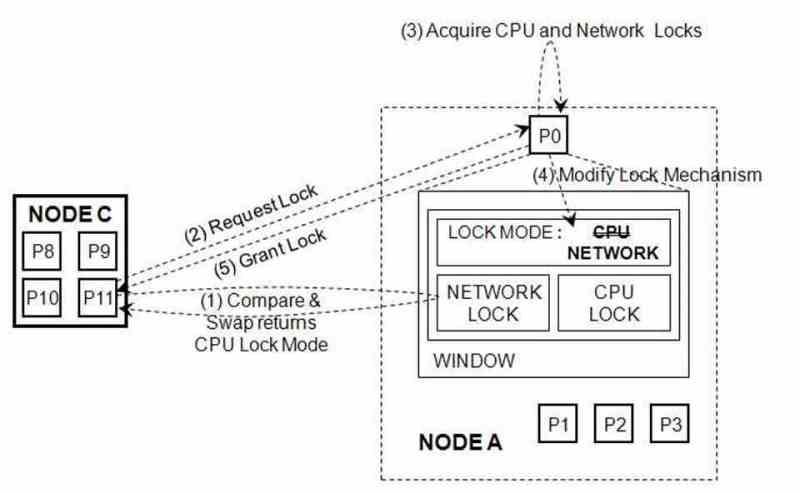
Lors de l’écriture d’un programme, il est codé dans une série d’instructions qui sont apparemment exécutées séquentiellement. Mais déjà avec le parallélisme des instructions avec un seul noyau en cours d’exécution, différentes unités d’exécution peuvent entrer. À cela, nous devons prendre en compte que l’exécution dans le désordre ajoute la complexité que l’accès à la mémoire et aux données au moment de l’exécution se fait de manière désordonnée.
Lorsqu’il y a un grand nombre de requêtes, cela finit par créer une contention pour accéder à la même mémoire. Cela entraîne un retard de plus en plus long des demandes, augmentant la latence de la mémoire avec le processeur sur certaines instructions et affectant la bande passante. Pour cela, il existe des mécanismes qui évitent au maximum ces conflits d’accès mémoire, de telle sorte que les processus accèdent à la mémoire à partir de la mémoire ordonnée. Cela permet d’éviter les conflits lors de la modification des données dans sa hiérarchie, ainsi que de réduire les problèmes de contention et par conséquent la latence d’accès.
Le moyen le plus simple d’y parvenir consiste à utiliser des verrous, qui sont des sections du code où nous marquons qu’ils ne doivent pas être exécutés simultanément par différents threads du processeur. C’est-à-dire qu’un seul noyau de celui-ci peut être responsable de cette partie du code. Nous avons donc fait un verrou sur le reste des cœurs et le reste ne pourra entrer dans l’exécution que lorsque l’instruction qui termine le verrou sera atteinte. Ce qui se produira lorsque la partie du code isolée de tous les noyaux sauf un sera terminée.
Qu’est-ce que la mémoire transactionnelle ?

Une méthode pour éviter les problèmes décrits dans la section précédente consiste à utiliser la mémoire transactionnelle. Ce qui n’est pas un type de mémoire ou de stockage, nous ne parlons donc pas d’un pur morceau de matériel. Son origine se trouve dans les transactions des bases de données, c’est un type d’instructions exécutées dans les unités Load-Store.
Le système de transaction dans un processeur fonctionne comme suit :
- Une copie de la partie de la mémoire à laquelle plusieurs cœurs veulent accéder est créée, une pour chaque instance.
- Chaque instance modifie sa copie privée indépendamment du reste des copies privées.
- Si une donnée a été modifiée dans une copie privée et pas dans le reste, alors la modification est également copiée dans le reste des copies privées.
- Si deux instances modifient les mêmes données en même temps et que cela crée une incohérence dans les données, les deux copies privées sont supprimées. et les copies privées du reste sont copiées
Le quatrième point est important, car c’est dans cette partie qu’il devient clair qu’il est nécessaire que cette partie du code soit sérialisée. Cela signifie que les autres instances arrêtent de modifier leurs copies privées et que les modifications sont effectuées par une seule des instances. Lorsqu’elle se termine, les modifications sont alors copiées dans le reste des copies privées. Lorsque la partie du code marquée comme transactionnelle a déjà été exécutée et que toutes les copies privées contiennent les mêmes informations, alors le résultat est copié dans les lignes de cache et les adresses mémoire correspondantes.
Systèmes de mémoire transactionnelle, l’Intel TSX
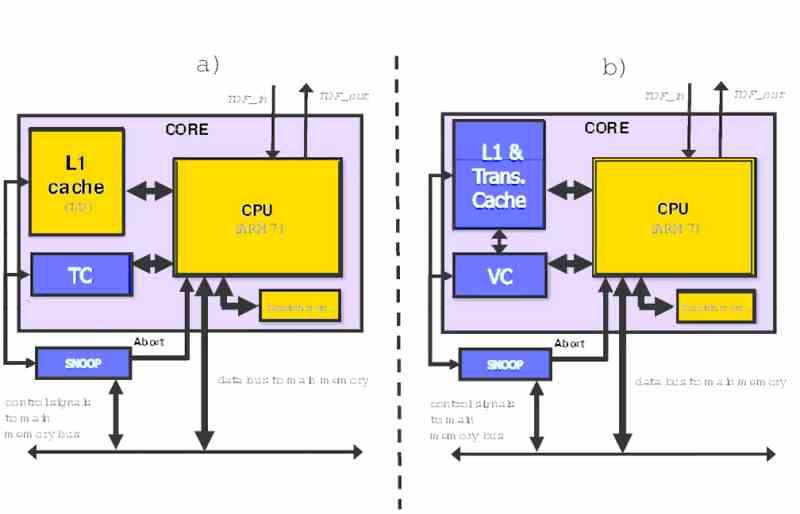
L’acronyme TSX, Extensions de synchronisation transactionnelle, reportez-vous à une série d’instructions supplémentaires à l’ISA x86, qui sont destinées à ajouter la prise en charge de la mémoire transactionnelle aux processeurs Intel. Par conséquent, c’est une série d’instructions et de mécanismes qui leur sont associés qui permettent de définir des sections spécifiques du code comme transactionnelles et que le processeur Intel exécute le processus dont nous avons discuté dans le processus précédent. Mais dans ce cas, l’implémentation Intel est un peu plus complexe. Puisque, comme nous l’avons vu précédemment, s’il y a un conflit entre deux données, l’ensemble du processus est interrompu par l’une des instances en cours d’exécution.
Sa mise en œuvre matérielle est réalisée en ajoutant un nouveau type de cache appelé cache transactionnel dans lequel les différentes opérations sont effectuées sur les différentes données. Gardez à l’esprit que la mémoire transactionnelle cherche à réduire les conflits lors de l’accès à la mémoire. Bien que les caches supportent un plus grand nombre de requêtes que la RAM en général, celles-ci sont également limitées et notamment aux niveaux les plus éloignés des cœurs. Tout cela est combiné à l’utilisation de mémoires internes et de registres privés qui servent de support aux copies privées exécutées par les différents cœurs.
Les instructions Intel TSX ne sont pas un ensemble complexe, nous avons d’une part l’instruction XBEGIN qui nous marque lorsqu’une section transactionnelle de mémoire commence, l’instruction XEND qui marque la fin et le XABORT, qui sert à marquer une sortie du processus lorsqu’une situation exceptionnelle survient.
La fin des instructions Intel TSX ?

Aujourd’hui, les unités de contrôle CPU sont en fait des microcontrôleurs complets, cela signifie que la façon dont elle décode les instructions et la liste des instructions peut être mise à jour. Intel a réalisé la première implémentation sur l’architecture Haswell et elle est restée jusqu’à présent dans les processeurs Intel. Depuis qu’il a récemment été désactivé via un micrologiciel sur les cœurs d’Intel de sixième, septième et huitième génération.
De temps en temps, Intel effectue des mises à jour à distance de ses processeurs, qui sont effectuées via le moteur de gestion Intel que nous avons dans notre PC à notre insu. Ils ne sont généralement pas courants mais peuvent inclure des optimisations de l’exécution de certaines instructions ou même l’élimination de la prise en charge d’autres. L’élimination de l’Intel TSX dans l’Intel Core est due au fait qu’avec les dernières modifications du microcode interne de l’unité de contrôle, cela implique un conflit dans le fonctionnement du logiciel, ce qui signifie que le CPU ne fonctionne pas comme il le devrait.
Mais la vraie raison est que l’Intel TSX permet l’exécution de code malveillant sous le radar des systèmes de sécurité classiques, notamment celui qui affecte le système d’exploitation. Car les copies privées ne correspondent pas à l’environnement de l’utilisateur ou au système d’exploitation. Par conséquent, il s’agit toujours d’un problème similaire à celui de l’exécution spéculative.