Nous entendons ou lisons souvent le fil conducteur du concept d’exécution lorsque nous entendons parler de nouveaux processeurs, mais aussi dans le monde du logiciel. C’est pourquoi nous avons décidé d’expliquer les différences entre ce que sont les processus ou threads d’exécution dans le logiciel et leurs équivalents significatifs dans le matériel.
Processus dans le logiciel

Dans sa définition la plus simple, un programme n’est rien de plus qu’une succession d’instructions ordonnées séquentiellement en mémoire, qui sont traitées par le CPU, mais la réalité est plus complexe. Toute personne ayant un peu de connaissances en programmation saura que cette définition correspond aux différents processus qui s’exécutent dans un programme, où chaque processus intercommunique avec les autres et se retrouve dans une partie de la mémoire.
Aujourd’hui, nous avons un grand nombre de programmes en cours d’exécution sur notre ordinateur et donc un nombre beaucoup plus important de processus, qui luttent pour accéder aux ressources CPU à exécuter. Avec autant de processus en même temps, il faut un chef d’orchestre pour les gérer. Ce travail est entre les mains du système d’exploitation qui, comme s’il s’agissait d’un système de contrôle du trafic dans une grande ville, est chargé de gérer et de planifier les différents processus qui vont être exécutés.
Cependant, les processus logiciels sont souvent appelés fils d’exécution, et ce n’est pas une mauvaise définition si l’on prend en compte leur nature, mais la définition ne coïncide pas dans les deux mondes, ils sont donc souvent confondus et cela conduit à plusieurs malentendus sur le fonctionnement du matériel et des logiciels multithreads. C’est pourquoi dans cet article nous avons décidé d’appeler les processus des threads logiciels pour les différencier des threads matériels.
Le concept d’une bulle ou d’un arrêt dans un processeur
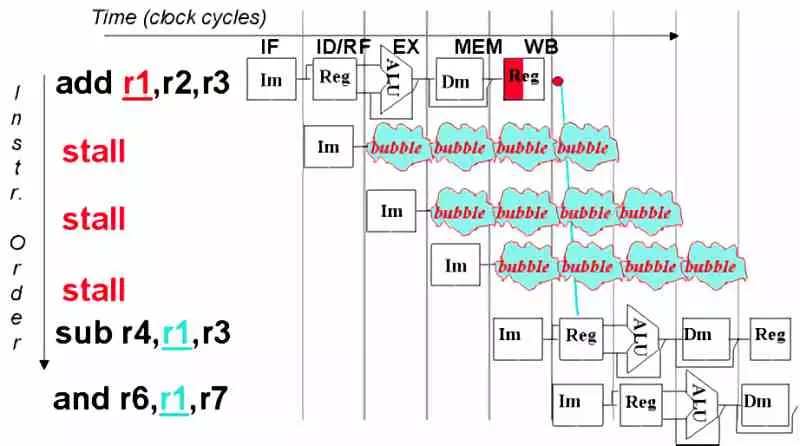
Une bulle d’exécution ou un blocage se produit lorsqu’un processus exécutant le processeur pour une raison quelconque ne peut pas continuer, mais n’a pas non plus été arrêté dans le système d’exploitation. Pour cette raison, les systèmes d’exploitation ont la possibilité de suspendre un thread d’exécution lorsque le processeur ne peut pas continuer et d’affecter le travail à un autre noyau disponible.
Dans le monde du hardware est apparu au début des années 2000 ce que l’on appelle le multithreading avec l’Hyperthreading du Pentium IV. L’astuce consistait à dupliquer l’unité de contrôle du CPU qui est responsable de la capture et du décodage. Grâce à cela, le système d’exploitation finira par voir le processeur comme s’il s’agissait de deux processeurs différents et attribuera la tâche à la deuxième unité de contrôle. Cela ne double pas la puissance, mais lorsque le processeur lui-même est bloqué dans un thread d’exécution, il passe immédiatement à l’autre pour profiter du temps d’arrêt qui s’est produit et obtenir plus de performances des processeurs.
Le multithreading au niveau matériel en dupliquant l’unité de contrôle, qui est la partie la plus complexe d’un processeur moderne, augmente complètement la consommation d’énergie. Par conséquent, les processeurs pour smartphones et tablettes n’ont pas de multithreading matériel dans leurs processeurs.
Les performances dépendent du système d’exploitation
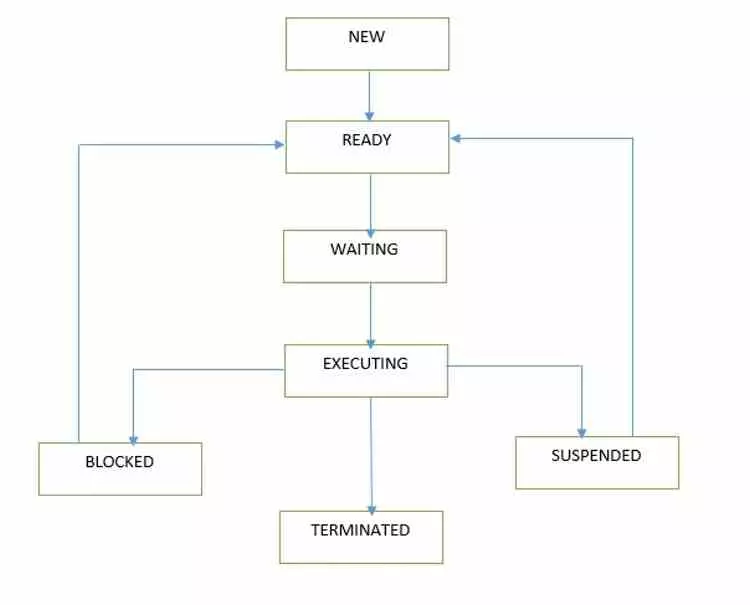
Bien que les CPU puissent exécuter deux threads d’exécution par cœur, c’est le système d’exploitation qui se charge de gérer les différents processus. Et aujourd’hui, le nombre de processus exécutés sur un système d’exploitation est supérieur au nombre de cœurs qu’un processeur peut exécuter simultanément.
Comme le système d’exploitation est en charge de gérer les différents processus, c’est aussi lui qui se charge de les affecter. C’est une tâche très facile si l’on parle d’un système homogène dans lequel chaque noyau a la même puissance. Mais, dans un système totalement hétérogène avec des cœurs de puissances différentes, c’est une complication pour le système d’exploitation. La raison en est qu’il a besoin d’un moyen de mesurer le poids de calcul de chaque processus, et cela ne se mesure pas seulement par ce qu’il occupe en mémoire, mais par la complexité des instructions et des algorithmes.
Le saut vers les cœurs hybrides s’est déjà produit dans le monde des processeurs ARM où les systèmes d’exploitation comme iOS et Android ont dû s’adapter à l’utilisation de cœurs de performances différentes fonctionnant simultanément. Dans le même temps, l’unité de contrôle des futures conceptions a dû être encore compliquée dans le x86. L’objectif? Que chaque processus du logiciel est exécuté dans le thread approprié du matériel et que c’est le CPU lui-même qui a le plus d’indépendance dans l’exécution des processus.
Comment se passe l’exécution des processus sur les GPUs ?

Les GPU de leurs unités de shader exécutent également des programmes, mais leurs programmes ne sont pas séquentiels, mais chaque thread d’exécution est composé d’une instruction et de ses données, qui ont trois conditions différentes :
- Les données sont situées à côté de l’instruction et peuvent être exécutées directement.
- L’instruction trouve l’adresse mémoire des données et doit attendre que les données arrivent de la mémoire aux registres de l’unité de shader.
- Les données dépendent de l’exécution d’un fil d’exécution précédent.
Mais un GPU n’exécute pas un système d’exploitation capable de gérer les différents threads. La solution? Tous les GPU utilisent un algorithme dans le planificateur de chaque unité de shader, l’équivalent de l’unité de contrôle. Cet algorithme est appelé Round-Robin et consiste à donner un temps d’exécution en cycles d’horloge à chaque thread d’exécution/instruction. Si cela n’a pas été résolu dans ce laps de temps, il va dans la file d’attente et l’instruction suivante de la liste est exécutée.
Les programmes de shader ne sont pas compilés dans le code, du fait qu’il existe des différences substantielles dans l’ISA interne de chaque GPU, le contrôleur est en charge de compiler et de conditionner les différents threads d’exécution, mais le code du programme est en charge de gérer eux. . C’est donc un paradigme différent de la façon dont le processeur exécute les différents processus.