Cependant, les feuilles de route sont souvent partiellement trompeuses ou changent au milieu d’elles, soit sous la forme d’annulations de produits et de dépassements d’autres. C’est pourquoi nous avons décidé de revoir non seulement la feuille de route du GPU Intel, mais nous avons essayé de la concilier avec les différentes informations qui nous parviennent.
La feuille de route du GPU Intel ARC et son architecture

L’architecture ARC Alchemist d’Intel ne diffère pas beaucoup de ce que propose la concurrence. Tout comme avec AMD et NVIDIA, nous utilisons différents signifiants pour les unités ayant des fonctionnalités identiques ou similaires. Nous allons donc être concis, nous allons nous concentrer sur ce qui est important.
L’objectif d’Intel est de capturer le plus de parts de marché possible et pour cela ils ne vont pas se prendre la jugulaire de leur rival en CPU, ce qu’ils veulent c’est aller contre NVIDIA et c’est pourquoi leurs Alchemist sont conçus pour rivaliser face à face avec le RTX 30. Donc, si nous comparons unité par unité, nous trouverons des choses comme une unité Ray Tracing très similaire et supérieure à celle d’AMD avec la possibilité de parcourir l’arbre BVH par matériel. L’équivalent Tensor Core qui ne se trouve pas dans les Radeon se trouve dans l’ARC Alchemist et le nombre d’ALU par unité de shader est de 128 au lieu de 64.
Ainsi, la première génération d’Intel ARC est plus une première entrée qui ne dit que peu ou rien sur l’ambition et les projets futurs d’Intel. Une simple lettre de motivation dans un marché jusqu’ici dominé par le duopole AMD et NVIDIA.
Le développement du Ponte Vecchio est essentiel

Nous savons deux choses sur le GPU pour le calcul haute performance appelé le Ponte Vecchio : la première est qu’il n’apparaîtra pas sur les PC, puisqu’il s’agit d’une conception pour les supercalculateurs et les systèmes de calcul haute performance. Cependant, il existe plusieurs concepts que nous allons voir dans la feuille de route Intel GPU. Bien que le plus important soit que les connaissances accumulées pour son développement soient ce qui leur permettra de déployer très rapidement les prochaines générations par rapport à la concurrence. Selon les mots de l’architecte en chef, Raja Koduri, on peut s’attendre à l’utilisation de la même unité dans le CPU et le GPU.
Meteor Lake sera une nouvelle architecture qui permettra d’intégrer des GPU (ou chiplets) en mosaïque dans un packaging 3D. C’est quelque chose de très excitant qui nous permettra d’offrir des performances de cartes graphiques dédiées avec l’efficacité des graphiques intégrés.
L’une des choses que Ponte Vecchio utilise est les nouvelles technologies d’emballage 3D et de pont en silicium d’Intel. Nous parlons de Foveros et d’EMIB, qui seront essentiels pour réaliser la feuille de route des GPU Intel ARC utilisant plusieurs tuiles ou chiplets au lieu d’une puce monolithique ou d’une seule pièce. Ils ne seront pas les seuls, mais ils ont plus progressé que la concurrence.
L’importance du nœud 3 nm de TSMC dans la feuille de route d’Intel

L’accord entre Intel et TSMC où ce dernier construira des GPU Tile pour ses graphiques et ses processeurs permettra à l’équipe de Pat Gelsinger de profiter du nœud taïwanais 3nm bien avant NVIDIA ou AMD. Le motif? La petite taille de chaque tuile est essentielle pour déployer rapidement les différentes générations de GPU ARC. Cependant, le GPU Tile développé pour le Ponte Vecchio n’est pas assez puissant pour affronter la RTX 4090 en termes de nombre d’ALU en FP32.
Intel a donc décidé de profiter de son accès privilégié au nœud 3nm pour créer un GPU Tile avec une puissance de calcul plus élevée que le Ponte Vecchio afin de proposer un GPU haut de gamme avec une puissance bien supérieure à celle que NVIDIA peut obtenir. avec le RTX 4090Ti. Pour ce faire, ils monteront les mêmes GPU Tile de Meteor Lake et Arrow Lake. La différence est que les GPU dédiés utiliseront des configurations de 2, 4 et qui sait si 6 et même 8 tuiles sur le même GPU.
Nous ne pouvons pas donner de chiffres officiels, mais on parle de configurations « 320 EU » par Tile GPU à 3 nm dans la feuille de route d’Intel, ce qui se traduit par 2560 ALU FP32 dans la configuration à 1 tuile uniquement, ce qui permettrait à Intel d’avoir un GPU avec plus de 20 000 « cœurs » dans le haut de gamme ; cependant, pour le moment, nous ne savons pas si nous la verrons comme Battlemage ou Celestial. En tout cas, le nom est le moins important de tous.
Comment Intel compte-t-il réunir plusieurs GPU différents en un seul ?
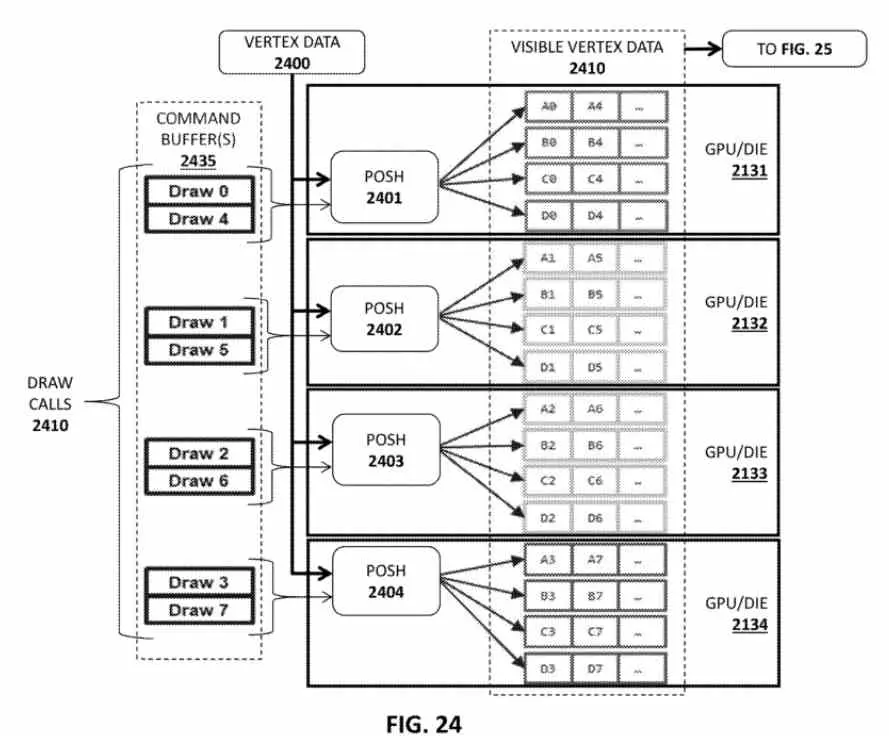
Nous entrons ici dans un sujet extrêmement intéressant, les GPU de bureau dessinent généralement avec une seule liste d’écrans par image, donc si nous en utilisons plusieurs, nous avons trois solutions :
- Trames alternées, ce qui signifie que la CPU devra avoir la liste d’écran des trames suivantes déjà préparées. Cela arrive au point où vous ne pouvez pas faire cela et vous ne pouvez pas évoluer sur les GPU.
- En divisant le cadre en plusieurs parties de l’écran, le problème est que toute la génération de la scène jusqu’à la pixellisation ne se fait pas au niveau de l’écran, mais au niveau de la géométrie du monde, donc c’est fait par un seul GPU.
L’idée d’Intel pour ses futurs GPU est facile à comprendre, d’abord la scène est rendue avec un seul GPU Tile, mais sans appliquer de programmes de shader à aucune primitive graphique et ni textures pour savoir où se trouvera chaque polygone de la scène depuis le début, sachant lesquels ne seront pas visibles et devront être jetés, notamment pour créer des listes d’écrans pour rendre la scène pour cibler chaque emplacement de la scène et donc faire en sorte que chaque tGPU rende sa propre partie de la scène.
Il s’agit ni plus ni moins d’adopter les mêmes solutions que le Tile Rendering, mais à la différence près que l’ordonnancement de la géométrie se fait avant le rendu final de la scène. Le pré-rendu pour créer la liste est effectué via le pipeline de calcul, ce qui permet d’utiliser plusieurs GPU Tile en parallèle dès le départ.