La mémoire HBM qui jusqu’à présent était liée aux GPU pour le marché du HPC commencera à être adoptée par les CPU. Qu’apporte-t-il et pourquoi la mémoire HBM sera-t-elle utilisée pour les processeurs et quelles sont les raisons d’Intel et d’AMD pour sa mise en œuvre?
Un examen de la mémoire HBM

La mémoire HBM est un type de mémoire composé de plusieurs puces de mémoire empilées, qui communiquent verticalement avec votre contrôleur en utilisant des chemins à travers le silicium. Un tel circuit intégré tridimensionnel est emballé ensemble et vendu sous forme de puce HBM.
Afin de communiquer avec le processeur, la puce HBM n’utilise pas d’interface série, mais communique plutôt avec le substrat ou l’interposeur ci-dessous pour transmettre les données. Cela vous permet de communiquer avec le processeur en utilisant un plus grand nombre de broches et de réduire la vitesse d’horloge pour chacune d’elles. Le résultat? Une mémoire RAM qui par rapport à un autre type consomme beaucoup moins lors de la transmission de données.
La mémoire HBM n’a pas été utilisée sur le marché domestique car elle est chère, sa composition de plusieurs puces mémoire la rend très difficile à fabriquer pour les produits à grande échelle, mais elle est idéale pour les produits à plus petite échelle. Que ce soit des GPU pour le calcul haute performance et même des CPU pour les serveurs où le HBM va faire son apparition,
Les canaux mémoire font partie de la clé
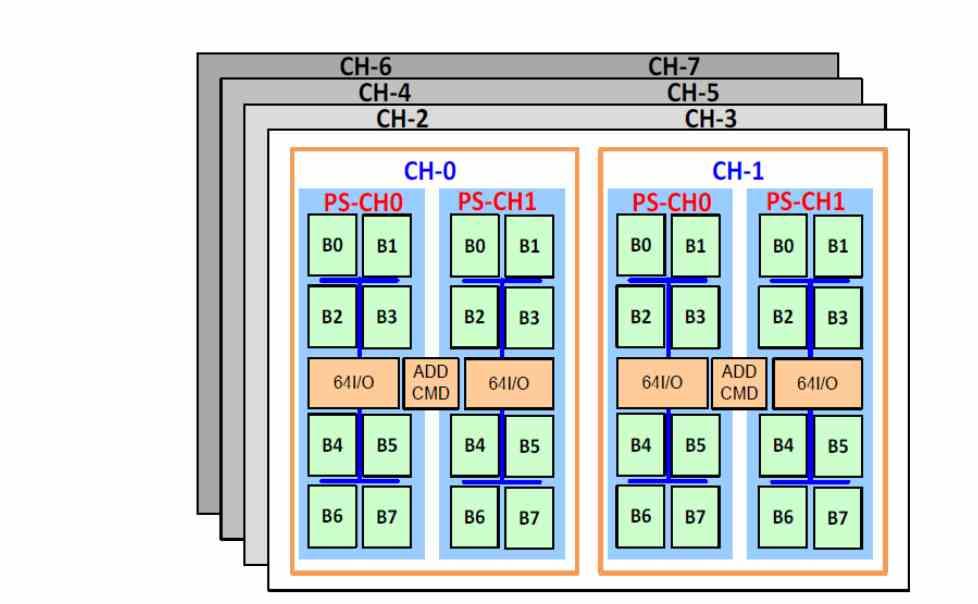
L’une des différences de la mémoire HBM par rapport aux autres types de mémoire est la prise en charge de jusqu’à 8 canaux de mémoire, qui est la configuration généralement utilisée dans les serveurs. Ainsi, les 8 canaux de la mémoire DDR4 sont remplacés par les 8 canaux de la mémoire HBM, qui ont une bande passante beaucoup plus élevée et une latence plus faible.
Latence inférieure? Eh bien oui, et tout cela du fait d’être sur le même substrat, cela signifie que les accès mémoire lors de l’exécution des instructions durent moins longtemps et donc qu’il y a moins de latence. Le handicap? La mémoire HBM2 a une capacité de stockage beaucoup plus petite et il est donc nécessaire d’ajouter une mémoire à un niveau inférieur de la hiérarchie.
Comme il a une latence inférieure à la DDR4, il est possible de placer le HBM comme mémoire pour le CPU au-dessus de la mémoire DDR4 dans la hiérarchie de la mémoire, et que les données sont vidées de la DDR4 vers la mémoire HBM au besoin et même d’utiliser la mémoire SSD NVMe en dessous avec une interface PCI Express assez rapide. Bien sûr, avec l’utilisation de la compression et de la décompression des données en temps réel du SSD vers la RAM.
Pourquoi un processeur serveur a-t-il besoin de la mémoire HBM?
La mémoire HBM se distingue surtout par son énorme bande passante, ce qui semble complètement exagéré pour un CPU, mais il faut tenir compte du fait que l’un des points sur lesquels NVIDIA a une grande présence sur le marché des serveurs est l’intelligence artificielle, grâce à l’ajout d’unités tensorielles dans leurs GPU depuis le lancement de Volta, de sorte que la grande majorité des systèmes utilisés pour la formation et l’inférence pour l’intelligence artificielle incluent de telles unités.
Quelle est la situation d’Intel et d’AMD? La réponse est d’ajouter ce type d’unités dans leurs serveurs, dans le cas d’Intel ce sont les unités AMX et dans AMD pour le moment on ne sait pas quelle unité ils vont implémenter. Mais tout l’intérêt de l’ajout de ces disques est de réduire le matériel NVIDIA pour les serveurs. Pour cela, nous devons garder à l’esprit qu’AMD a une division graphique qui rivalise avec NVIDIA, mais nous ne pouvons pas oublier Intel Xe HPC et Intel Xe HP par Intel.
Les lecteurs pour l’IA nécessitent beaucoup de bande passante pour fonctionner, en ce sens qu’ils sont parfaitement en ligne avec les GPU, c’est pourquoi NVIDIA vend ses GPU sous le nom de PU «AI» ou vice versa. Dans le même temps, c’est la raison pour laquelle l’utilisation de la mémoire HBM sera ajoutée aux CPU, afin de les convertir en unités qui doublent à la fois pour l’IA et les CPU.
Une évolution qui s’est produite avant

Dans les années 1990, les unités DSP ont été utilisées pour accélérer les applications multimédias émergentes. Où sont ces unités actuellement? Ils ont disparu dès que les unités SIMD ont été implémentées dans les CPU et que l’implémentation d’une unité DSP pour l’accélération des algorithmes multimédias n’était plus nécessaire.
Dans le cas de l’IA, le concept est le même, l’idée d’implémenter des unités de tenseur dans les CPU des serveurs cherche à pouvoir se passer des GPU pour ces tâches. Donc, d’un point de vue commercial pour Intel et AMD, le message peut se résumer comme suit: « N’achetez pas de GPU avec des unités pour l’IA alors que vous pouvez déjà le faire sur le CPU. »
Les GPU NVIDIA doivent leur puissance à l’IA grâce au grand nombre d’unités de shader ou SM, par exemple le GA102 a 82 SM dans sa configuration, ce qui est bien plus que le nombre de cœurs dans un processeur de bureau. Dans un processeur de serveur, nous parlons de dizaines de cœurs, par exemple, l’AMD EPYC peut atteindre jusqu’à 64 cœurs et se développera dans les prochaines générations. Avec cela, nous pouvons mieux comprendre comment l’adoption de la mémoire HBM dans les processeurs des serveurs sera, en particulier face à un marché avec des applications de plus en plus centrées sur l’IA.