Il y a eu pendant des années un écosystème d’applications et d’outils autour de CUDA axé sur le monde de la science et de l’ingénierie et sur les différentes branches de chacun. De la médecine à la conception automobile. Cela a permis à NVIDIA de se développer au-delà du matériel de jeu sur PC et d’étendre sa part de marché potentielle.
CUDA est plutôt une philosophie pour programmer des algorithmes à exécuter sur un GPU NVIDIA, bien qu’il existe également des possibilités de le faire sur un processeur central et même sur la puce d’un concurrent. Actuellement, il existe plusieurs langages de programmation qui ont les extensions CUDA correspondantes. Ceux-ci inclus: C, C++, Fortran, Python et MATLAB.
Que sont les noyaux CUDA ?
Dans le monde du matériel que nous utilisons le mot core comme synonyme de processeur et c’est là que le terme noyaux CUDA entre en conflit avec la tradition générale. Imaginez un instant qu’un fabricant de moteurs de voiture vous vende un moteur à 16 soupapes et le marque comme « 16 moteurs ». Eh bien, NVIDIA appelle les unités chargées d’effectuer des calculs mathématiques des cœurs, comment s’appelle chaque processeur les unités logiques arithmétiques ou ALU en anglais sont ce que sont les cœurs CUDA dans un GPU NVIDIA. Plus précisément, les unités capables de fonctionner avec des nombres à virgule flottante de précision 32 bits sont généralement comptées.
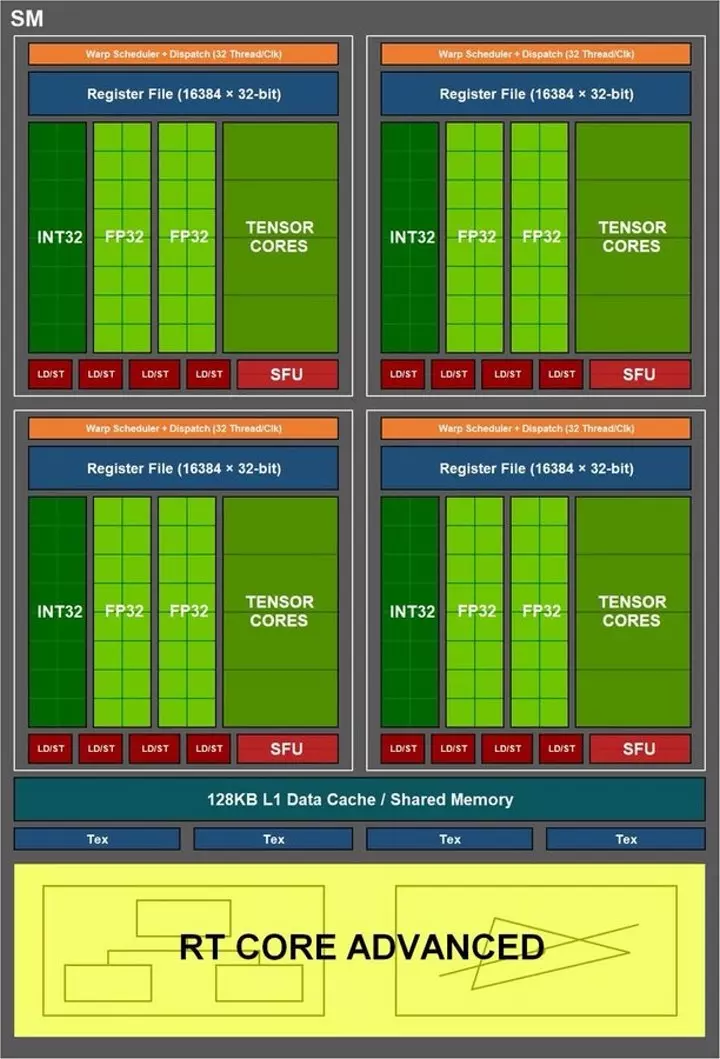
Dans le cas des cartes NVIDIA, quel est le les équivalents réels d’un cœur ou d’un processeur sont appelés SM. Ainsi, par exemple, un RTX 3090 Ti malgré 10 752 cœurs CUDA a en fait 84 cœurs réels, puisque c’est le nombre de vrais SM. Pensez qu’un processeur doit être capable d’exécuter tout le cycle d’instructions par lui-même et non une seule partie, comme c’est le cas avec les soi-disant « cœurs CUDA ».
NVIDIA CUDA par rapport aux processeurs de flux AMD, en quoi sont-ils différents ?
Pas du tout, puisqu’AMD ne peut pas utiliser la marque CUDA car elle appartient à son rival, il utilise la marque Stream Processors. Dont l’utilisation est également incorrecte et loyale pour les mêmes raisons.

Soit dit en passant, un processeur de flux ou un processeur de flux dans sa définition correcte est tout processeur qui dépend directement de la bande passante de sa mémoire RAM associée et non de la latence. Ainsi, une puce graphique ou un GPU l’est, mais un CPU qui dépend davantage de la latence ne l’est pas. D’autre part, étant donné que les puces NVIDIA et AMD comprennent différents binaires, il est impossible d’exécuter un programme CUDA sur un GPU non NVIDIA.
| Cœurs NVIDIA CUDA | Processeurs de flux AMD | |
|---|---|---|
| Qui sont? | Unités ALU | Unités ALU |
| Où sont-elles? | Sur les GPU NVIDIA | Sur les GPU AMD |
| Peuvent-ils exécuter des programmes CUDA ? | Oui | Non |
Existe-t-il différents types de cœurs NVIDIA CUDA ?
Nous appelons généralement les unités à virgule flottante de précision 32 bits comme noyaux CUDA, mais d’autres types d’unités sont également inclus dans la définition, à savoir :
- Unités ALU avec la capacité de travailler avec des nombres à virgule flottante à double précision, c’est-à-dire 64 bits.
- Unités entières 32 bits.
Parce que les GPU n’utilisent pas un système de parallélisme par rapport aux instructions, ce qui est fait est d’utiliser l’exécution concurrente. Où une unité d’un type peut remplacer un autre type dans l’exécution d’une instruction. C’est une capacité que les puces NVIDIA ont à partir de l’architecture Volta, dans le cas des systèmes de bureau, à partir du RTX 20.
En échange, CE NE SONT PAS DES CŒURS CUDAles lecteurs SM suivants sur le GPU :
- Tensor Cores, qui sont responsables de l’exécution des opérations avec des matrices. En général, ils sont utilisés pour l’IA et dans les graphiques, ils disposent d’utilitaires tels que DLSS pour augmenter automatiquement la résolution.
- RT Cores, qui calculent les intersections des rayons dans toute la scène pendant le Ray Tracing.
- Les SFU, qui ont la capacité d’exécuter des instructions mathématiques complexes plus rapidement que les ALU conventionnelles. Les instructions prises en charge incluent les opérations trigonométriques, les racines carrées, les puissances, les logarithmes, etc.
Qui, bien qu’il s’agisse également d’unités arithmétiques-logiques, ne sont pas comptées par NVIDIA en tant que telles.
Comment fonctionnent les noyaux CUDA ?
De manière générale, les cœurs CUDA fonctionnent de la même manière que n’importe quelle unité de ce type, si nous parlons plus spécifiquement, nous devons comprendre ce qu’est un fil d’exécution pour une puce graphique contemporaine et le séparer conceptuellement du même concept dans un processeur central .
Dans un programme exécuté sur une CPU, un thread d’exécution est un programme avec une série d’instructions qui exécutent une tâche spécifique. D’autre part, dans un GPU, chaque donnée a son propre fil d’exécution. Cela signifie que chaque sommet, polygone, particule, pixel, morceau, texel ou toute autre primitive graphique a son propre thread exécuté sur l’un des cœurs CUDA.
Comment les instructions sont-elles exécutées dans le noyau CUDA ?
De plus, la façon d’exécuter les threads, et c’est généralement le cas sur tous les GPU, consiste à utiliser une variante de l’algorithme Round-Robin. Qui consiste en:
- Les instructions sont classées en groupes en fonction du nombre de cycles d’horloge nécessaires pour s’exécuter à partir de chacun des ALU/processeurs de flux/cœurs CUDA.
- Si l’instruction d’un thread n’a pas été exécutée dans le temps imparti, elle est déplacée vers la file d’attente et la suivante dans la liste est exécutée. Qui ne doit pas nécessairement correspondre au même thread d’exécution que le premier.
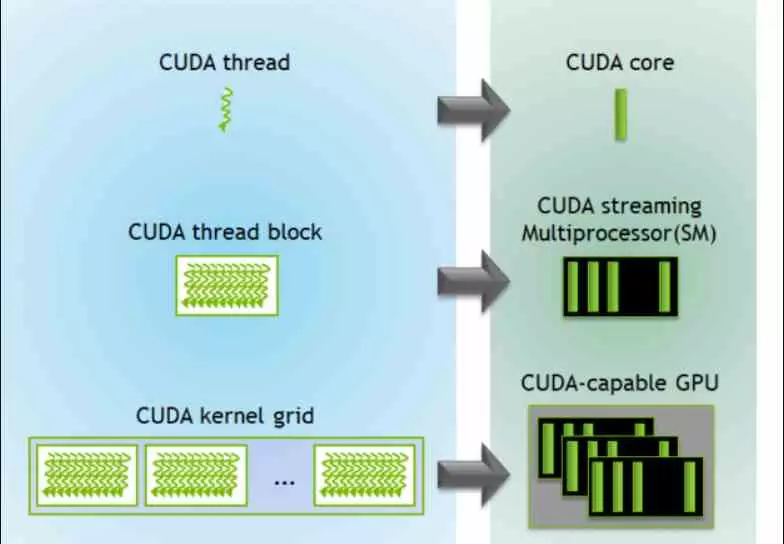
Gardez à l’esprit que les scènes 3D complexes d’aujourd’hui sont composées de millions d’éléments visuels pour former les scènes complexes et qu’elles sont formées à une vitesse suffisamment rapide. Par conséquent, les cœurs CUDA sont la base pour traiter tous ces éléments en parallèle et à grande vitesse.
Leur grand avantage est qu’ils exécutent directement les données présentes dans les registres et donc dans la mémoire interne de chaque SM. Par conséquent, ils ne contiennent pas d’instructions pour un accès direct à la VRAM. Au contraire, l’ensemble de l’écosystème est conçu de manière à ce que les threads soient poussés de la mémoire vers chacun des cœurs du GPU. Cela évite les goulots d’étranglement dans l’accès à la mémoire. Cela implique un changement par rapport au modèle traditionnel d’accès à la mémoire. En dehors de cela, chacun des SM où se trouvent les cœurs CUDA est beaucoup plus simple dans de nombreuses fonctions qu’un cœur de processeur.
Les noyaux CUDA ne peuvent pas exécuter de programmes conventionnels
Les threads d’exécution qui exécuteront les noyaux CUDA sont créés et gérés par le processeur central du système et sont créés en groupes par l’API lors de l’envoi des listes de commandes graphiques ou de calcul. Lorsque le processeur de commandes de la puce graphique lit les listes de commandes, elles sont classées en blocs qui sont chacun distribués à un SM ou à un cœur réel différent. A partir de là, l’ordonnanceur interne décompose les threads d’exécution selon le type d’instruction et les regroupe à exécuter.
Cela signifie qu’ils ne peuvent pas exécuter de programmes conventionnels, en raison de ce fonctionnement particulier des cœurs dans les GPU des cartes graphiques, car leur nature les en empêche. C’est pourquoi vous ne pouvez installer aucun système d’exploitation ni exécuter aucun programme conventionnel dessus.