La symbiose entre DirectX et les concepteurs de matériel est claire, l’API Microsoft permet la communication avec les différents composants tels que le GPU à partir d’un modèle abstrait d’entre eux et permet aux développeurs de mettre en œuvre les dernières améliorations dans leurs jeux. Soit pour obtenir de meilleures performances, soit de meilleurs graphismes et un meilleur son.
Qu’entend-on par Shader Model?

Les shaders sont des programmes qui s’exécutent dans les cœurs des GPU et qui modifient les valeurs d’une primitive graphique à un certain point de la 3D ou du pipeline de données si l’on parle de calcul via des GPU. Ces programmes sont écrits dans un langage de haut niveau qui, dans le cas de DirectX de Microsoft, est appelé HLSL.
Au fur et à mesure que les GPU s’améliorent, de nouvelles fonctions HLSL sont ajoutées qui permettent l’utilisation des nouvelles fonctions d’un GPU, certaines d’entre elles correspondent aux futures conceptions de NVIDIA, Intel et AMD qui n’ont pas encore été implémentées dans un GPU commercial, mais si dans un pour aller sur le marché.
Qu’est-ce qui a été ajouté dans le Shader Model 6.6?
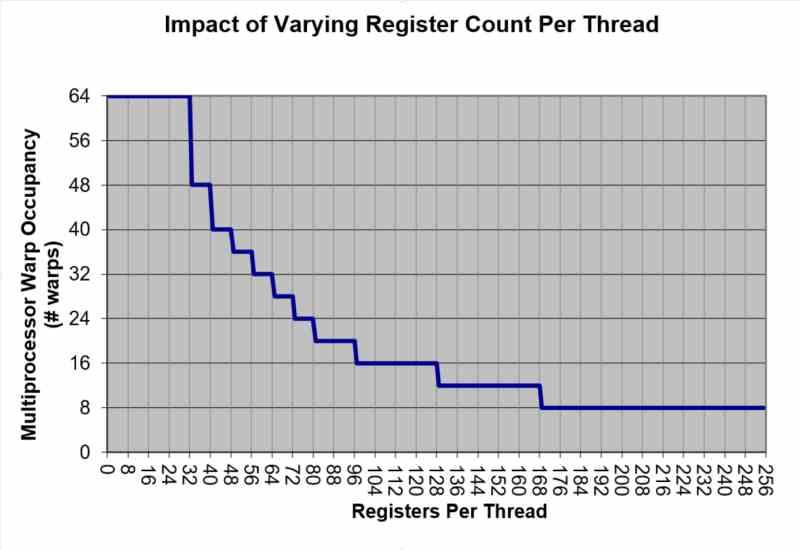
Les cœurs des GPU, connus sous le nom d’unités de shader en général, bien qu’avec des noms comme SM de NVIDIA et Compute Unit d’AMD, sont en charge de l’exécution des programmes. Celles-ci se présentent sous la forme de noyaux où chaque noyau est une donnée et une instruction à exécuter. Les données peuvent provenir du noyau lui-même, cela peut être un pointeur mémoire ou dépendre du calcul d’un noyau précédent.
Les noyaux sont regroupés en vagues et en fonction de leur taille, le niveau d’occupation dans les registres d’unité de shader sera plus ou moins élevé. Qu’est-ce que cela signifie? Eh bien, au niveau d’utilisation du shader unit et donc de ses performances, car cela peut conduire à ne pas utiliser toute la puissance du GPU pour le calcul. Plusieurs fois, la taille d’une onde n’atteint pas tous les registres, entraînant la perte d’une partie de la performance.
Le changement du shader Model 6.6? Il sera désormais possible de créer des vagues de taille variable, ce qui permettra de combler les lacunes non utilisées et donc de faire usage de toutes les ALU de chaque unité SIMD, permettant ainsi une meilleure utilisation des GPU.
Est-ce pour les GPU actuels?

Dans DirectX, les éléments ne sont généralement pas ajoutés qui ne peuvent pas être utilisés avec le matériel disponible sur le marché, nous pouvons donc supposer qu’au moins il existe une architecture NVIDIA. Intel ou AMD qui peuvent profiter de cette nouveauté. Ça oui, le code du jeu doit être optimisé, alors ne vous attendez pas à son ajout dans les jeux qui sortiront cette année, car c’est une fonction que Microsoft vient d’ajouter. Bien que cela aidera à la création de profils optimisés de jeux existants sur des GPU pouvant exécuter plusieurs vagues par unité SIMD.
Il se peut que NVIDIA et AMD aient fait des changements a priori dans leur RTX 30 et RDNA 2. Comme avec le DirectStorage qui peut être utilisé dans le RTX 20. On peut donc trouver une surprise, même si on ne peut pas exclure Intel avec son Intel Xe-HPG qui devrait apparaître cette année.
Pour permettre l’utilisation d’ondes de taille variable par le programme, il est nécessaire de changer l’ordonnanceur ou l’unité de contrôle de l’unité de shader. Pour le moment, on pense qu’ils utilisent une seule onde par unité SIMD, donc s’il n’y a pas assez de registres occupés, alors il n’y a pas assez d’ALU. Avec ce changement, si par exemple un GPU prend en charge une vague de 32 noyaux, alors nous pouvons avoir une vague de 24 composants et une autre de 8 fonctionnant en même temps. Ce changement ne rend pas un GPU plus rapide qu’il ne l’est, mais le rend plus performant à 100%, cela, oui, avec le bon code.