La principale préoccupation dans la conception des processeurs n’est souvent pas d’obtenir le plus de puissance, mais les meilleures performances lors de l’exécution des instructions. Nous entendons la performance comme le fait d’approcher l’idéal théorique du fonctionnement d’un processeur. Il est inutile d’avoir le processeur le plus puissant si, en raison de limitations, la seule chose qu’il a est le potentiel d’être et ne l’est pas.
Deux manières de gérer le parallélisme
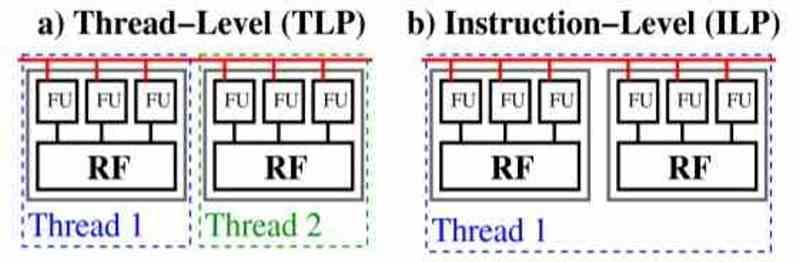
Il existe deux façons de traiter le parallélisme dans le code d’un programme, il s’agit du parallélisme au niveau des threads ou ILP et du parallélisme pédagogique ou TLP.
Dans le TLP, le code est divisé en plusieurs sous-programmes, qui sont indépendants des autres et fonctionnent de manière asynchrone, ce qui signifie que chacun d’eux ne dépend pas du code du reste. Lorsque nous sommes dans un processeur TLP, la clé est que si un arrêt d’exécution se produit pour une raison quelconque, le processeur TLP prend un autre des threads d’exécution et met celui inactif en attente.
Les processeurs ILP sont différents, leur parallélisme est au niveau de l’instruction et donc dans le même thread d’exécution, ils ne peuvent donc pas tricher en mettant le thread principal en attente. De nos jours, les processeurs combinent les deux types d’exécution, mais l’ILP est toujours exclusif aux processeurs et c’est là qu’ils obtiennent un grand avantage en termes de code série par rapport au code entièrement parallélisable.
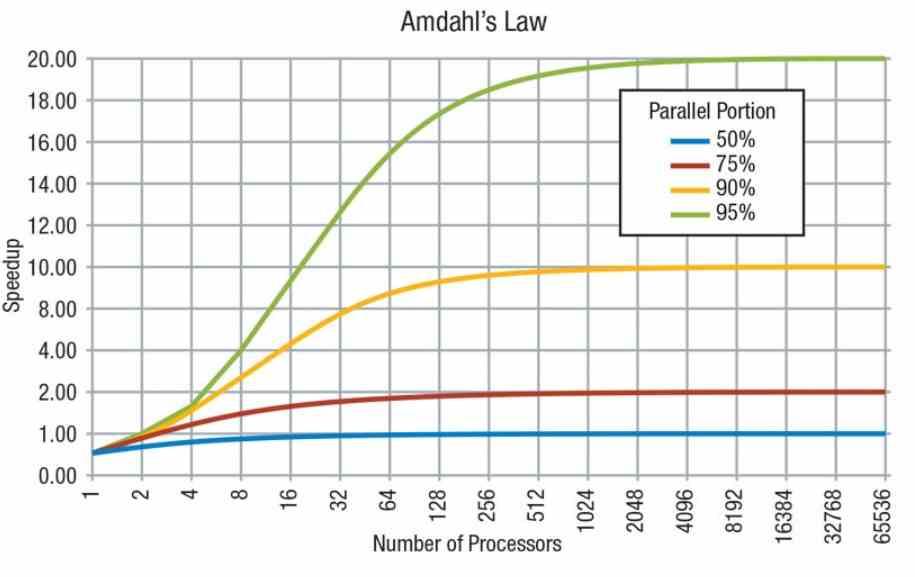
Nous ne pouvons pas oublier que selon la loi d’Amdahl, un code est composé de parties en série, qui ne peuvent être exécutées que par un seul processeur, et en parallèle, qui peuvent être exécutées par plusieurs processeurs. Cependant, tout ne peut pas être parallélisé et certaines parties du code en série nécessitent un fonctionnement en série.
Au cours des 15 dernières années, le concept a été développé dans lequel des algorithmes parallèles sont exécutés dans des GPU, dont les cœurs sont de type TLP, tandis que le code série est exécuté dans des CPU de type ILP.
Exécution dans l’ordre des instructions
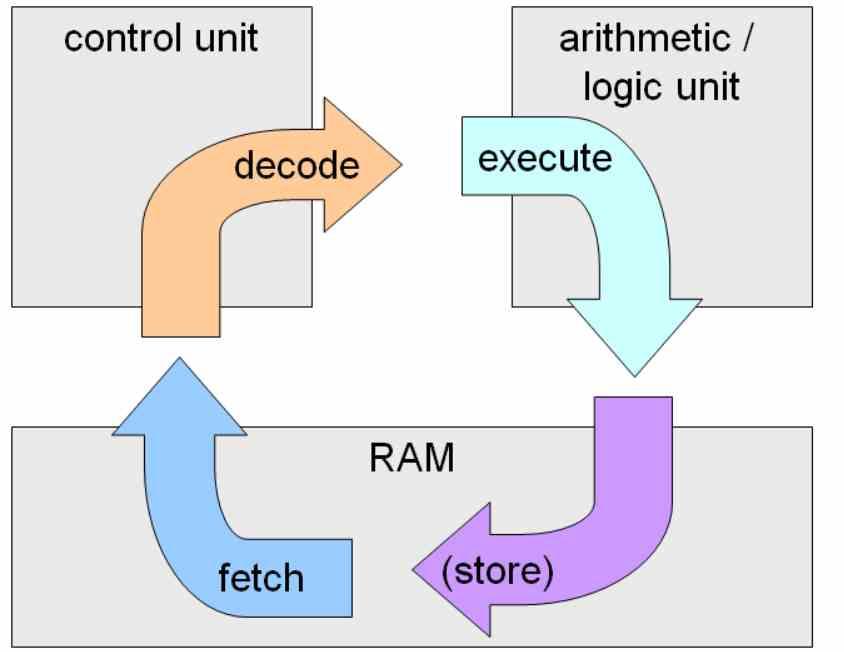
L’exécution dans l’ordre est l’exécution d’instruction classique, son nom est parce que les instructions sont exécutées dans l’ordre dans lequel elles apparaissent dans le code et l’instruction suivante ne peut pas continuer tant que la précédente n’a pas été résolue.
La plus grande difficulté de l’exécution dans l’ordre réside dans les instructions conditionnelles et de saut, car elles seront exécutées lorsque la condition se produit, ce qui ralentit considérablement la vitesse d’exécution du code. C’est un énorme problème lorsque le nombre d’étages dans un processeur est extrêmement élevé, ce qui se produit lorsqu’un processeur fonctionne à des vitesses d’horloge élevées.
Le piège pour atteindre des vitesses d’horloge élevées est de segmenter la résolution des instructions au maximum avec un grand nombre de sous-étapes du cycle d’instructions. Lorsqu’un saut ou une condition erronée se produit, un nombre considérable de cycles d’instructions est perdu.
Hors service, accélération de l’ILP

Le désordre ou l’exécution dans le désordre est la manière dont les processeurs les plus avancés exécutent le code et on pense éviter que l’exécution s’arrête. Comme son nom l’indique, il consiste à exécuter les instructions d’un processeur dans un ordre différent de ceux indiqués dans le code.
La raison pour laquelle cela est fait est que chaque type d’instruction a un type d’unité d’exécution qui lui est assigné. Selon le type d’instruction, la CPU utilise un type d’unité d’exécution ou un autre, mais ceux-ci sont limités. Cela peut provoquer un arrêt de l’exécution, donc ce qui est fait est d’avancer l’instruction suivante dans son exécution, pointant dans une mémoire ou un registre interne qui est l’ordre réel des instructions, une fois qu’elles ont été exécutées, elles sont renvoyées dans l’ordre d’origine dans lequel ils étaient dans le code.
L’utilisation du désordre vous permet d’augmenter le nombre moyen d’instructions résolues par cycle et de le rapprocher de l’idéal de performance. Par exemple, le premier Intel Pentium avait une exécution dans l’ordre et était un processeur capable de travailler avec deux instructions contre le 486 qui ne pouvait fonctionner qu’avec une seule, mais malgré cela, ses performances dues aux arrêts n’étaient que de 40% supplémentaires.
Étapes supplémentaires en cas de panne
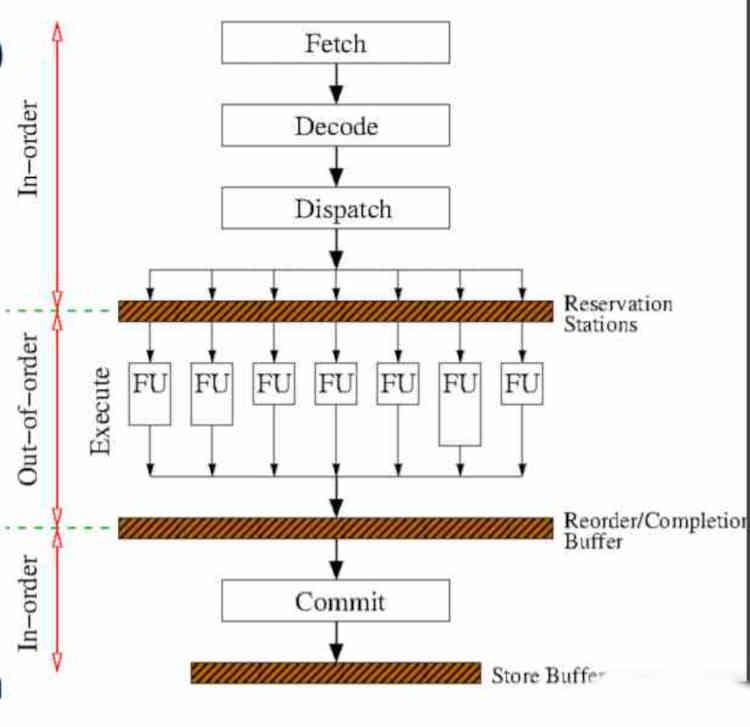
La mise en œuvre de l’exécution dans le désordre ajoute des étapes supplémentaires au cycle d’instructions, dont nous avons déjà parlé dans l’article intitulé Voici comment votre CPU exécute les instructions données par le logiciel, que vous pouvez trouver dans sosordinateurs.com.
En fait, seule la partie centrale de l’exécution de l’instruction varie par rapport à l’exécution dans l’ordre, ces changements interviennent avant l’étape d’exécution, donc les deux premiers qui sont récupérés et décodés Ils ne sont pas affectés, mais deux nouvelles étapes sont ajouté, qui se produisent avant et après l’exécution des instructions.
La première étape est les stations de réserve, dans lesquelles le matériel attend que les unités d’exécution soient libres. Sa mise en œuvre est complexe, car elle repose sur un mécanisme qui non seulement surveille quand une unité d’exécution est libre, mais compte également la durée moyenne en cycles d’horloge de chaque instruction en cours d’exécution pour savoir comment elle doit réorganiser les instructions.
La deuxième étape est le tampon de réorganisation, qui est chargé de trier les instructions par ordre de sortie. Gardez à l’esprit que pour accélérer la sortie des instructions dans l’exécution dans le désordre, toutes les branches d’instructions spéculatives du code sont exécutées. L’instruction spéculative est celle qui est donnée lorsqu’il y a un saut conditionnel, que la condition soit remplie ou non. C’est donc à ce stade que les branches d’exécution non confirmées sont écartées.